
- 系统背景与动机:
- 随着大型语言模型(LLMs)的广泛应用,对服务工作负载的需求变得多样化,需要满足不同级别的服务级别目标(SLOs)。
- Kimi作为一个模型即服务(MaaS)提供商,旨在最大化整体有效吞吐量,同时满足SLOs的约束。
- Mooncake架构:
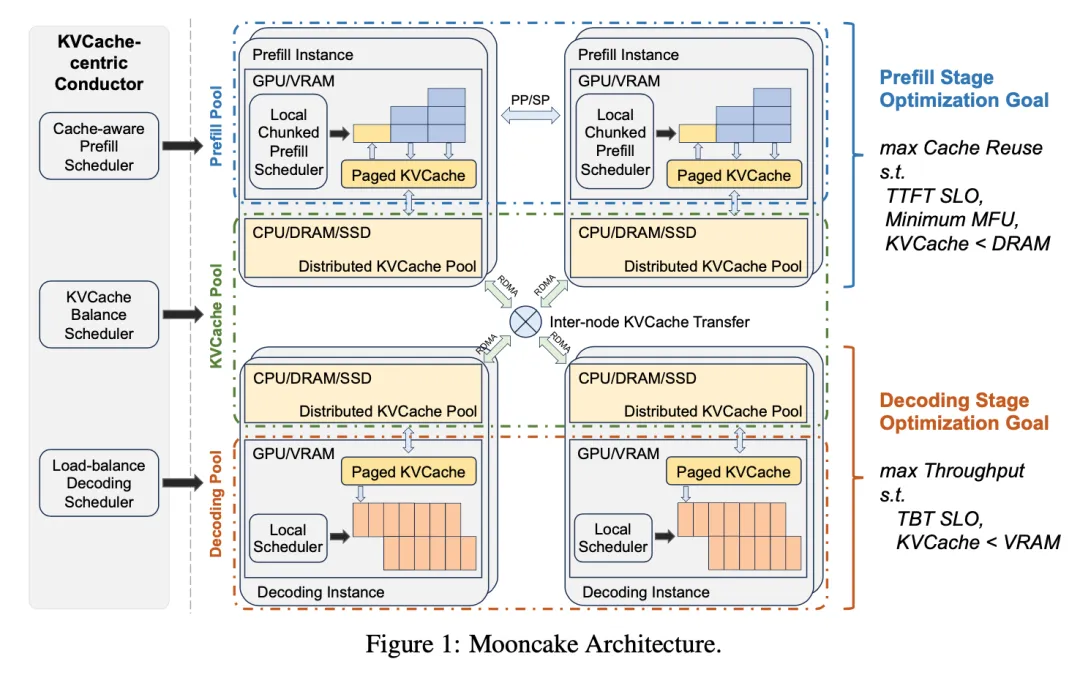
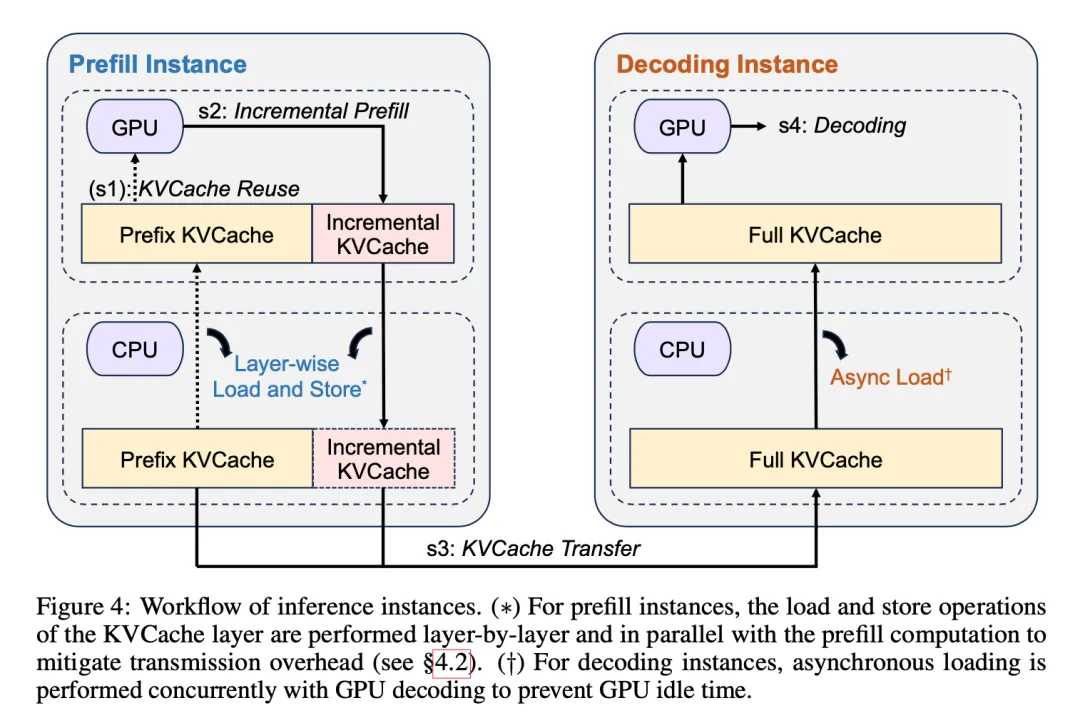
- Mooncake采用了分离架构,将预填充(prefill)节点与解码(decoding)节点分开,并实现了分离的KVCache,优化了资源利用。
- 系统设计:
- 系统设计包括全局调度器(Conductor),预填充节点池,解码节点,以及KVCache的管理和传输。
- 引入了分块流水线并行机制(Chunked Pipeline Parallelism, CPP)来处理长上下文输入,减少首次Token时间(TTFT)。
- 调度算法:
- 描述了以KVCache为中心的请求调度算法,平衡实例负载和用户体验(通过TTFT和Token间时间TBT SLOs测量)。
- 包括基于启发式的自动热点迁移方案,无需精确预测KVCache使用情况即可复制热门块。
- 过载处理:
- 面对用户请求量的快速增长,Mooncake实现了早期拒绝策略,以减少过载场景中浪费的计算资源。
- 通过预测未来负载来缓解由早期拒绝引起的负载波动问题。
- 性能评估:
- 使用公共数据集、模拟数据和真实工作负载对Mooncake进行了端到端性能评估。
- 实验结果显示,Mooncake在长上下文场景中表现出色,与基线方法相比,能够显著提高吞吐量并满足更多的请求。
- 未来工作:
- 文章提到了Mooncake面临的挑战和未来的发展方向,包括进一步优化预填充和解码阶段的架构,以及开发更精确的负载预测能力。
- 开源与专有信息:
- 文章中提到,为了保护专有信息并促进可复制性,所有实验结果都是基于虚拟模型的重放跟踪,且该跟踪将稍后开源。
文章还提供了Mooncake在GitHub上的地址,供有兴趣的读者进一步探索和研究。
原文地址:
https://mp.weixin.qq.com/s/4SBRZKAjqcS2MkvnFPey_g
本文地址:https://www.163264.com/8464