

今日简讯 2024.6.28
– 针对当前AI系统导致能源消耗加快的问题,比尔·盖茨发起了“辩护”,他认为AI技术最终将会“抵消”其耗电量。
– Reddit 最近宣布更改其机器人排除协议,以阻止AI公司未经授权地爬取其内容或要求它们付费。
– 吴恩达计划为其AI基金筹集超过1.2亿美元,展现了他在人工智能领域的持续投入和影响力。
– 为癌症患者提供治疗方案,软银与美国医疗 IT 企业 TempusAI 成立合资公司。
– OpenAI 与《时代》达成合作协议:可用其杂志内容训练 ChatGPT。
– Resemble AI发布了深度伪造检测模型Detect-2B,准确率达到约94%,在30多种语言的音频检测上表现出色。
– 备受瞩目并且备受资金支持的AI搜索工具Perplexity被曝引用错误的AI生成垃圾信息,这些信息来自可疑的博客和LinkedIn文章。
– OpenAI 宣布基于 GPT-4 训练了一个名为 CriticGPT 的模型,用于查找 ChatGPT 聊天机器人输出内容中的错误。(有意思的是搞出来的这个人已经离职了,超级对齐负责人 Jan Leike)
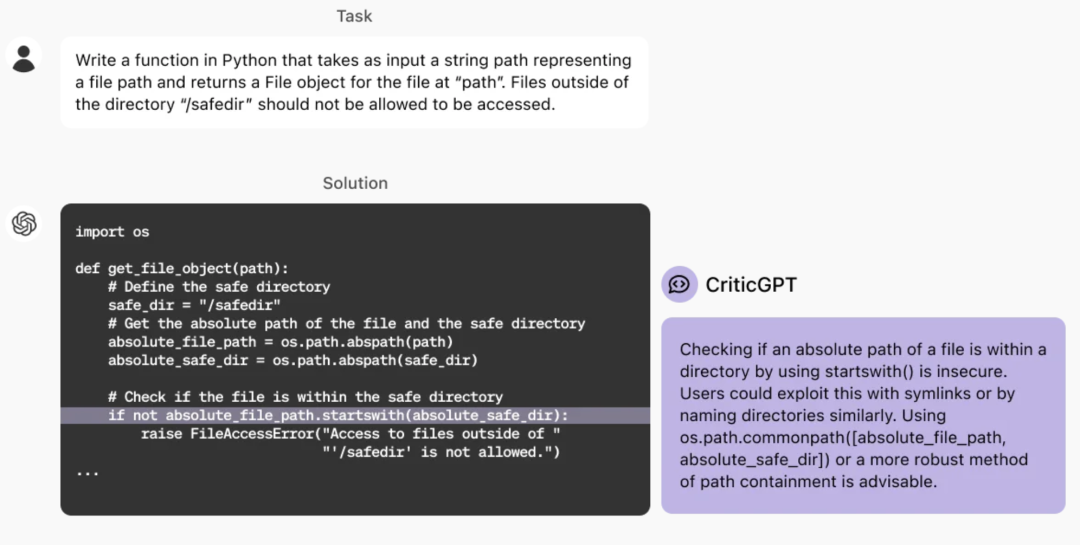
原文:https://openai.com/index/finding-gpt4s-mistakes-with-gpt-4/
AI 编码这个赛道卷起来了~百度也推出了文心快码(Baidu Comate)
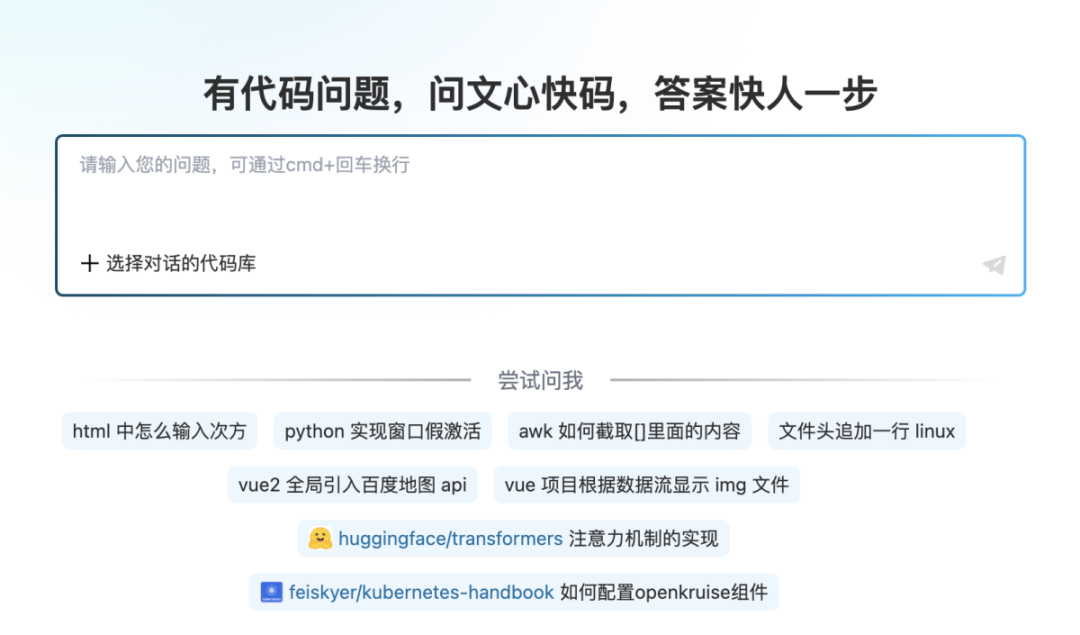
文心快码提供 4 大版本,标准版,专业版,企业版,企业专有版。目前文心快码支持的 IDE 有 Visual Studio Code(兼容 1.70 及以上)、JetBrains IDEs(兼容 2021.1 及以上。(昨天字节才推出了豆包 MarsCode)
体验地址:
https://comate.baidu.com/zh/chat
Google 开源了 Gemma 2 的 9B 和 27B 版本,同时Gemini 1.5 Pro 上 200 万 Token 上下文向所有开发者开放
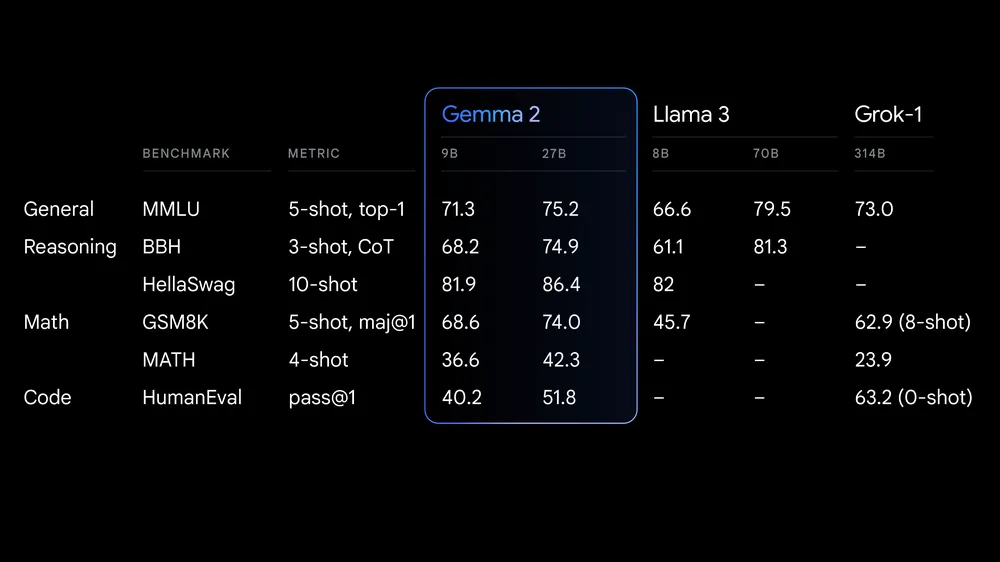

9B参数规模的Gemma 2模型在其类别中也表现卓越,超越了其他同规模的开源模型。Gemini 1.5 Pro现在开放了200万个token的context window,Gemini API中增加了代码执行功能,Google AI Studio中增加了Gemma 2模型。
地址:
https://blog.google/technology/developers/google-gemma-2
Meta 发布基于 Code Llama 的 LLM 编译器:优化代码大小、反汇编
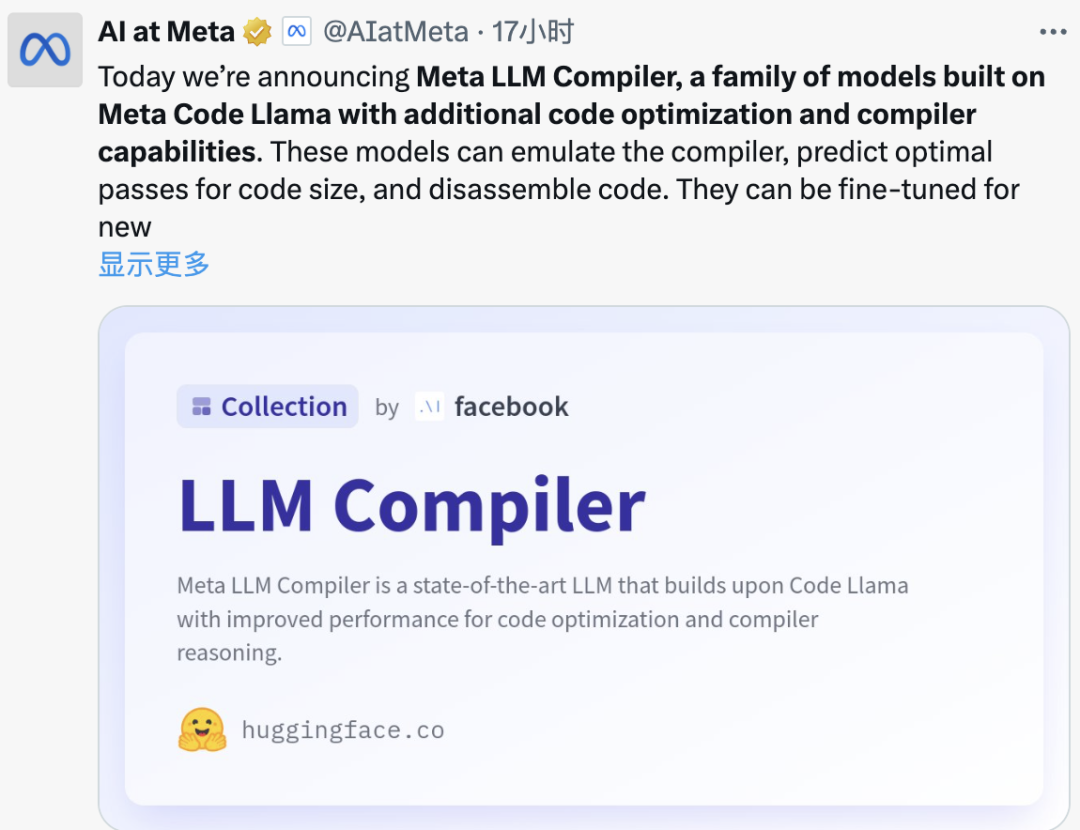
这些模型可以模拟编译器,预测代码大小的最佳传递,并可反汇编代码,可以针对新的优化和编译器任务进行微调。Meta 在 HuggingFace 上公开了 LLM 编译器的 7B 和 13B 模型,采用宽松的许可协议,允许用于研究和商业用途。
地址:
https://huggingface.co/collections/facebook/llm-compiler-667c5b05557fe99a9edd25cb
世界上最快的语音机器人演示
速度对于语音 AI 接口非常重要。人们期望在正常对话中能够快速做出反应。该演示展示了低延迟 LLM 交互,旨在实现 500 毫秒的语音到语音响应时间。
体验地址:
https://fastvoiceagent.cerebrium.ai/
ToucanTTS:语音合成界的“万语之王” 支持超7000多种语言

ToucanTTS不仅能说多种语言,还能模拟不同说话人的风格,无论是语调、重音还是节奏,都能轻松拿捏。
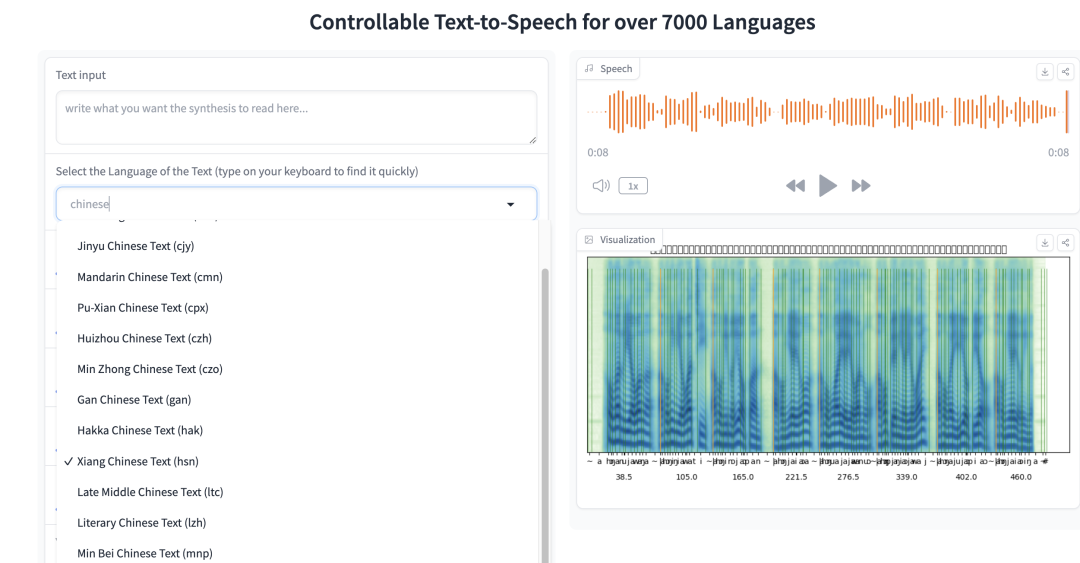
甚至我看到了中国各地方言代码~
项目地址:
https://github.com/DigitalPhonetics/IMS-Toucan
体验地址:
https://huggingface.co/spaces/Flux9665/MassivelyMultilingualTTS
character ai 的语音通话功能全量上线了
来源:https://mp.weixin.qq.com/s/n37XbKB9KWXyKHMjJQy1KQ
本文地址:https://www.163264.com/8419