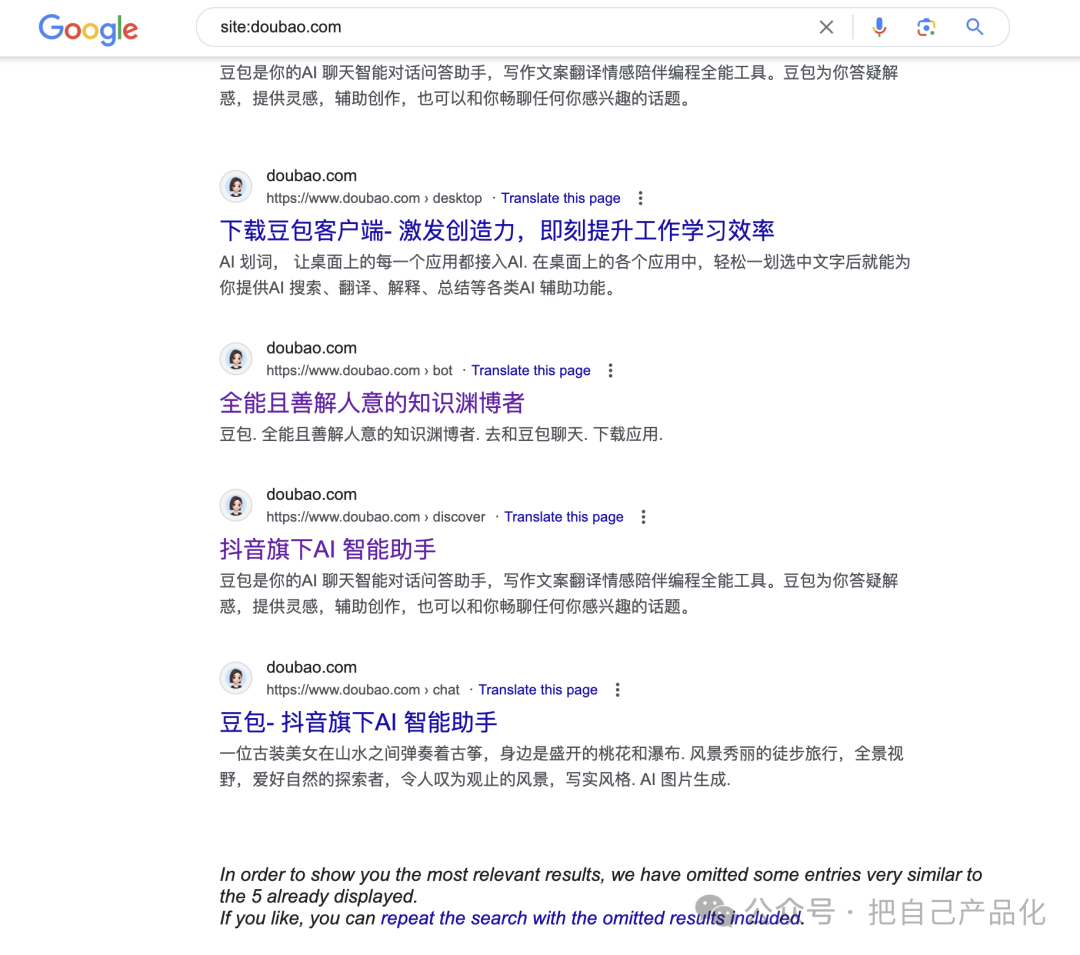
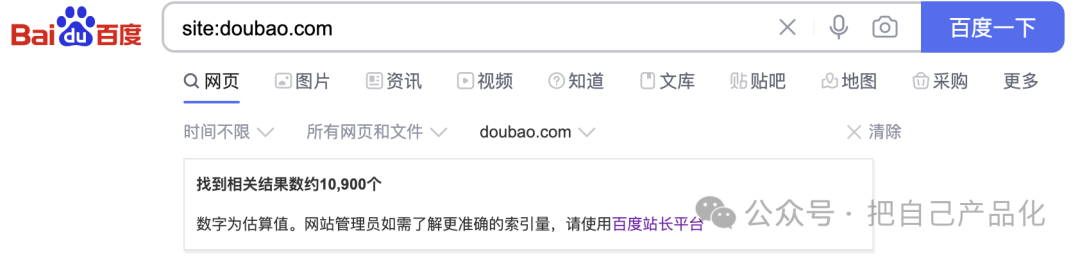
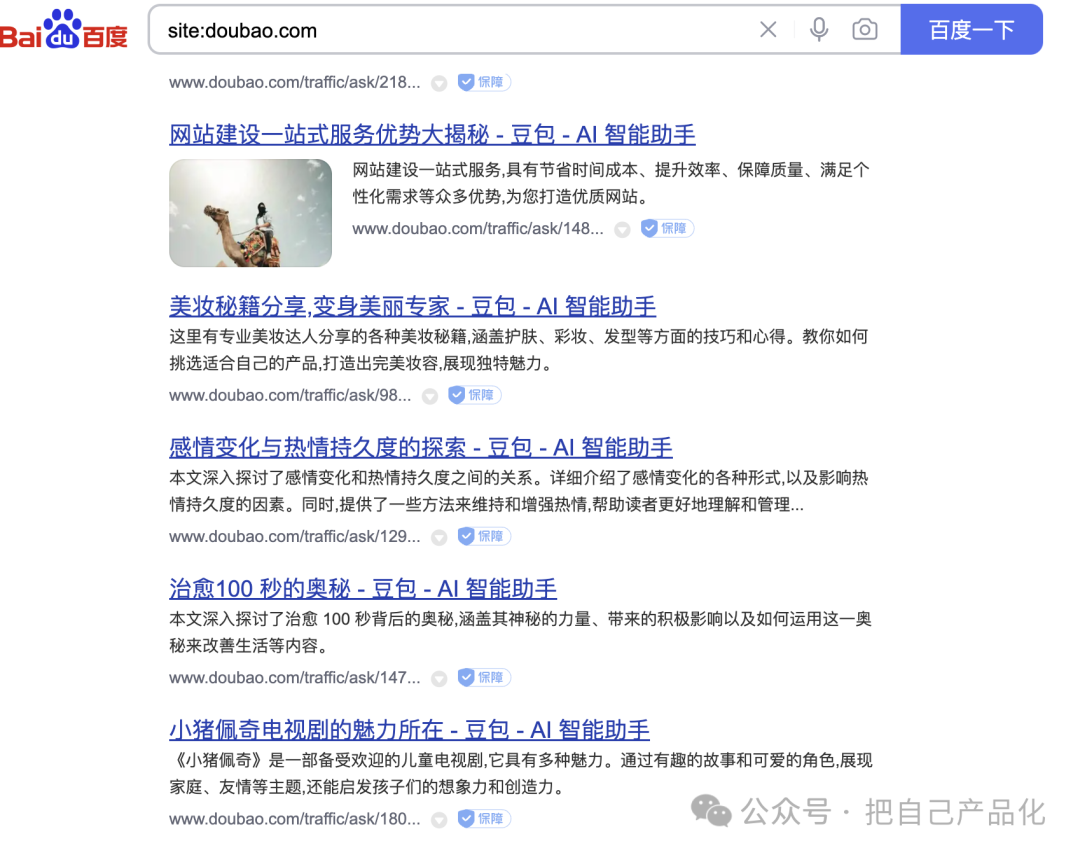
这两天有个新闻,闹的还挺大的,就是字节旗下的豆包“投毒事件。”简单来说,就是豆包通过平台上的智能体生成了海量的数据,这些数据被包括 Google 和百度在内的搜索引擎收录了。然后这些数据被做 AI 搜索的,如perplexity.ai回答用户问题的时候引用了,因为这个内容是豆包里的 AI 跟用户的互动内容,内容质量很差,被用户吐槽了。因为实在影响大厂形象,目前豆包已经改进了,Google 已经找不到太多痕迹(根据网友的截图,显示收录的网页高达 1500 万以上),但是百度还有很多证据……这个东西就叫「内容农场」,在当年做网站搞 SEO的时候特别流行, 活到现在的大部分互联网公司过去都或多或少干过这事儿,哪怕现在,很多公司依然在搞,只是没想到换成 AI 之后,这个效果就是单车变摩托。PS:说到这里,真的不得不再次吐槽一下马斯克的 X 了,它那个搜索真的太烂太烂了,无论你搜什么,基本上都被「黄赌为主的垃圾内容」占满了。你要想知道啥叫「垃圾内容农场」,你看到 x 的搜索结果就知道了。 小公司搞我能理解,包括我自己也会做一些自动化的内容推送出去,毕竟需要曝光,需要流量嘛,自然就想方设法跟搜索引擎斗智斗勇,所以才会出现所谓搜索权重之分,简单粗暴的理解就是如果你是大公司或者机构我就更信任你,权重高,你要是个人,我对你不是那么信任,需要长时间观察,所以权重低。于是你就会看到百度甚至显示的都是自己家的产品的内容,微博上你搜东西也会发现有时候只显示蓝 V。 但事实上,哪怕到现在利用这个“钻空子”的,不要脸的大公司和机构一点也不少。比如那些挂着蓝 V 利用自身权重各种蹭流量甚至搞虚假宣传的到处都是。真实的人性有时候就是这样:因为我信你,所以方便你更好地坑我。豆包这事儿,主要是出在内容太 AI 八股文(首先,其次,最后),从方法上来说其实到也没什么毛病,这不就是传统大厂标准玩法么,尤其是背着增长 KPI 的人这就是凭本事吃饭啊,搞不好其他公司也偷偷这么搞了,“效果”没豆包这么好而已。所以你看,平台多重要啊,同样的活儿,换个地儿就显得「so easy」。我担心的倒是,以前你要批量造内容起码还是有成本的,而现在有了 AI 加持,成本就低了很多,同时造出来的质量虽然不能完全跟人相比,但也比以前的高出不知道多少倍。那自然避免不了,会有无数 AI 生成的内容充斥在互联网上。 而 AI 不就是靠吃着我们人类贡献的各种数据成长的么,还是边吃边拉,总有一天。它拉的会比吃的还多,那不是迟早会吃到它自己生成的内容上来?这不就相当于自己拉出了什么又给吃了回去?这能健康?或者这就是它抛弃人类的那一天? 看来,这将是一个长期拉扯的过程。甚至一段时期内,还得面临怎么去判断这个信息是真的还是 AI 编的,那你说这个过程是更容易了还是更难了? 这应该就是每一个新技术出现时候伴随着的一体两面吧。