
什么是𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 𝗔𝘂𝗴𝗺𝗲𝗻𝘁𝗲𝗱 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 ( 𝗥𝗔𝗚 ) 𝗦𝘆𝘀𝘁𝗲𝗺𝘀 ?
以下是一个基于 RAG 的简单聊天机器人示例,用于查询您的私人知识库。
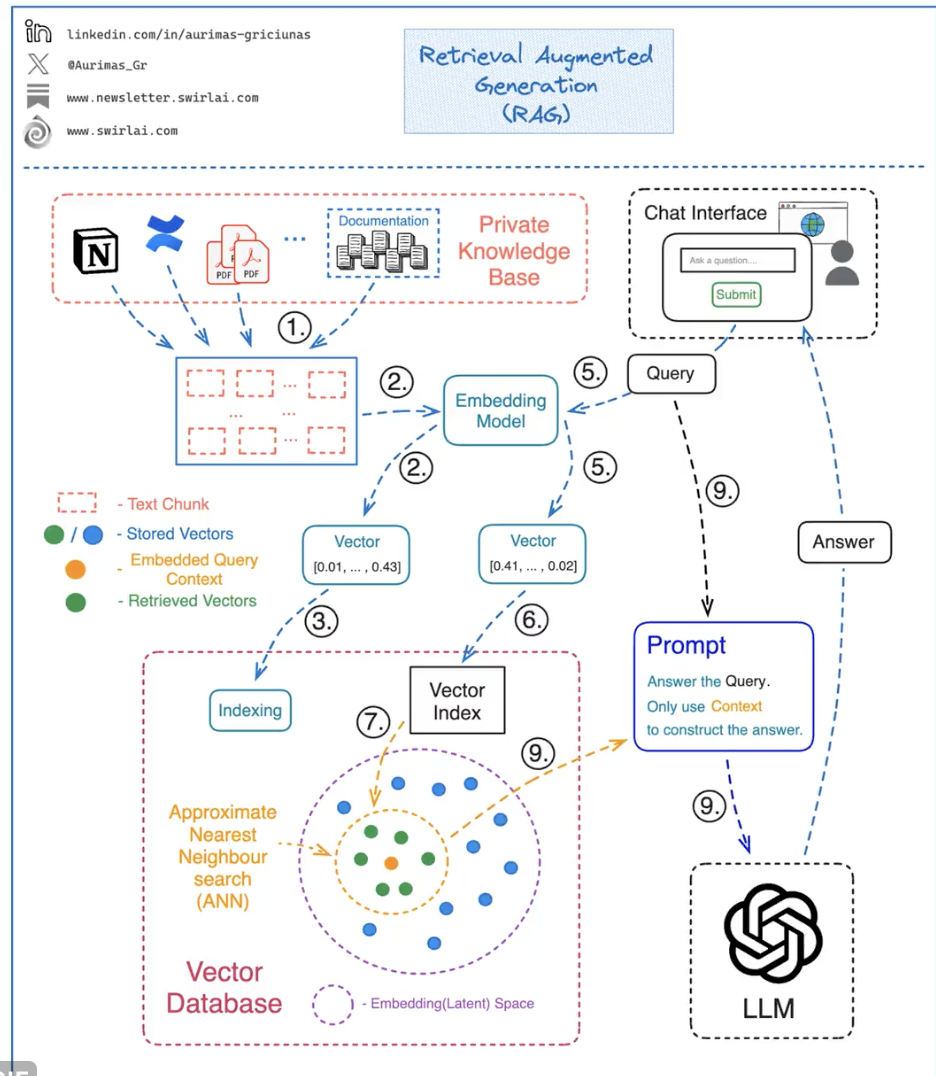
第一步是以适合查询的格式存储内部文档的知识。我们通过使用嵌入模型嵌入它来做到这一点:
𝟭 :将整个知识库的文本语料库分割成块——一个块将代表可查询的单个上下文。感兴趣的数据可以来自多个来源,例如 Confluence 中的文档并辅以 PDF 报告。
𝟮 :使用嵌入模型将每个块转换为向量嵌入。
𝟯 :将所有向量嵌入存储在向量数据库中。
𝟰 :分别保存表示每个嵌入的文本以及指向嵌入的指针(稍后我们将需要它)。
接下来我们可以开始构建感兴趣的问题/查询的答案:
𝟱 :使用与嵌入知识库本身相同的嵌入模型来嵌入您想要询问的问题/查询。
𝟲 :使用生成的向量嵌入对向量数据库中的索引运行查询。选择您想要从矢量数据库中检索的矢量数量 – 它将等于您将检索并最终用于回答查询问题的上下文数量。
𝟳 :向量 DB 对索引中提供的向量嵌入执行近似最近邻 (ANN) 搜索,并返回先前选择的上下文向量数量。该过程返回给定嵌入/潜在空间中最相似的向量。
𝟴 :将返回的向量嵌入映射到表示它们的文本块。
𝟵 :通过提示将问题与检索到的上下文文本块一起传递给 LLM。指示法学硕士仅使用提供的上下文来回答给定的问题。这并不意味着不需要提示工程 – 您需要确保 LLM 返回的答案落入预期范围内,例如,如果检索到的上下文中没有可使用的数据,请确保没有编造答案假如。
要使其成为真正的聊天机器人 – 使用 Web UI 面对整个应用程序,该 UI 公开文本输入框以充当聊天界面。通过步骤 1. 至 9. 运行提供的问题后 – 返回并显示生成的答案。这就是当今大多数基于单个或多个内部知识库源的聊天机器人的实际构建方式。
在构建 RAG 系统时您可能会遇到许多注意事项,我将在接下来的几周内介绍它们。
本文地址:https://www.163264.com/6861