
昨天清华大学和商汤公司的这个视频生成项目可以让开源视频模型也具备类似Runway的运动笔刷能力。而且比Runway更进一步,支持在涂抹区域后使用画笔描绘运动方向,也可以分开使用。
希望可以与现有的开源视频生成模型兼容,我在论文中没有看到相关内容。
详细介绍:
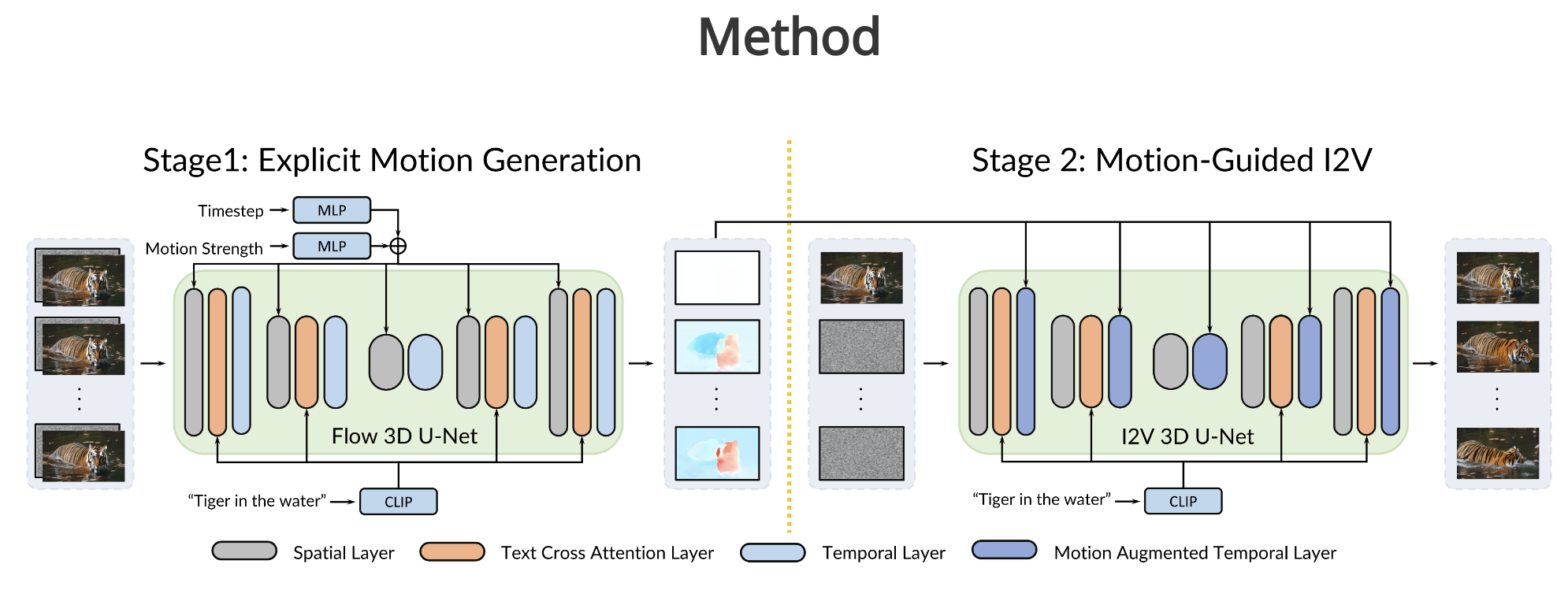
我们推出了一种名为Motion-I2V的创新框架,用于实现一致且可控的图片到视频转换(I2V)。与以往直接学习复杂映射关系将图片转换为视频不同,Motion-I2V将这一过程分为两个阶段,并明确加入了运动模型。
在第一阶段,我们设计了一种基于扩散理论的运动场预测技术,主要用于推算参考图片中各像素点的移动轨迹。在第二阶段,我们引入了一种结合运动数据的时间序列注意力机制,该机制可以改进视频生成中常用且功能有限的一维时间序列注意力方法。这个改进可以高效地将参考图片的特征信息传递到根据第一阶段预测的轨迹生成的视频帧中。
相较于现有技术,Motion-I2V即使面对大幅度的运动和视角变化,也能创造出更为一致的视频。通过为第一阶段配备一个专门的稀疏轨迹控制网络(ControlNet),Motion-I2V允许用户通过少量的轨迹和区域标注来精确控制运动轨迹和运动区域,这比单纯依赖文本指令进行控制提供了更多的灵活性。
此外,Motion-I2V的第二阶段还自然地支持了零样本转换,即不需要样本训练的视频到视频转换。通过定性和定量的比较,我们发现Motion-I2V在生成一致性和可控性强的视频方面优于以往的方法。
项目地址:
https://xiaoyushi97.github.io/Motion-I2V/
本文地址:https://www.163264.com/6396