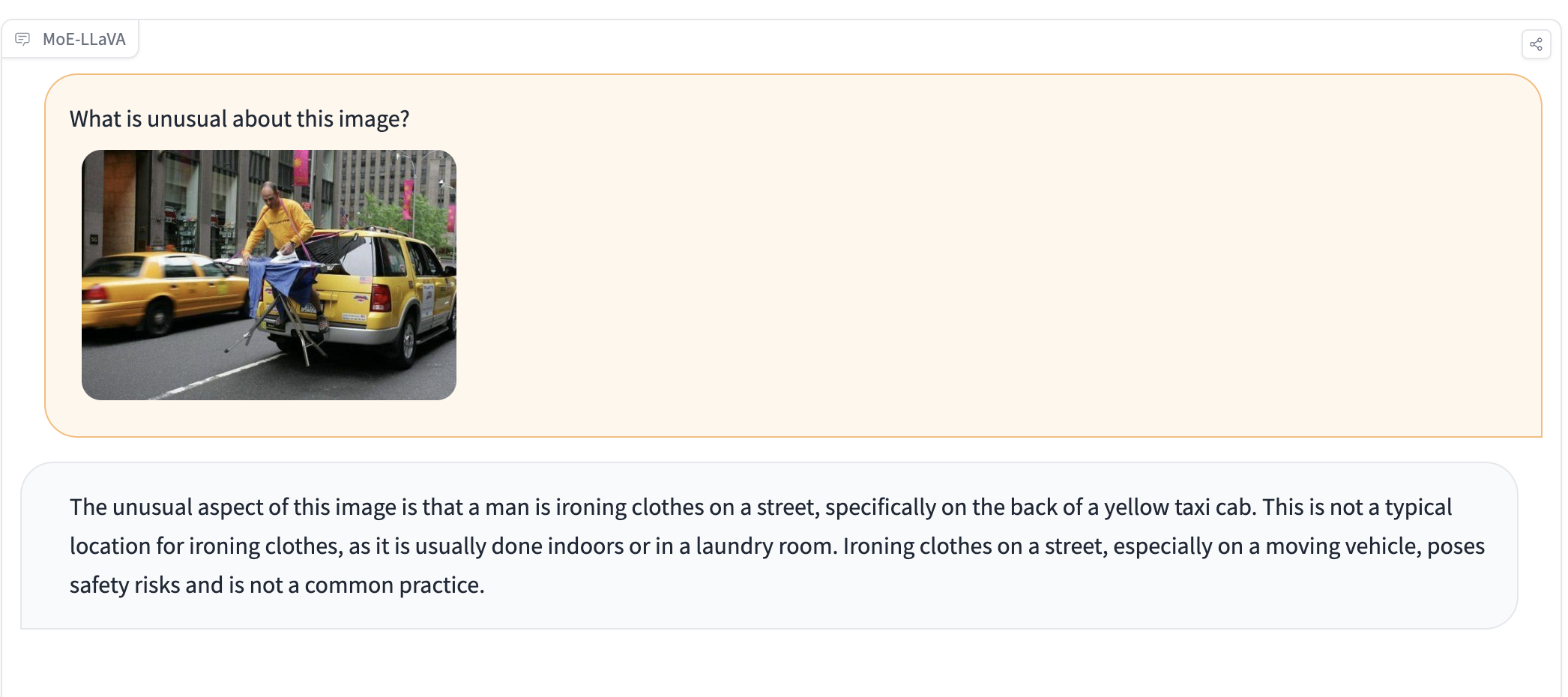

MoE-LLaVA:多模态的混合专家模型 北大的开源项目,3B的资源占用,媲美7B的能力。 只有3B个稀疏激活参数,与LLaVA-1.5-7B在各种视觉数据集上表现相当,在物体幻觉基准测试中超越了LLaVA-1.5-13B。
论文地址:
https://arxiv.org/pdf/2401.15947.pdf
在线体验:
https://huggingface.co/spaces/LanguageBind/MoE-LLaVA
项目地址:
https://github.com/PKU-YuanGroup/MoE-LLaVA
本文地址:https://www.163264.com/6379