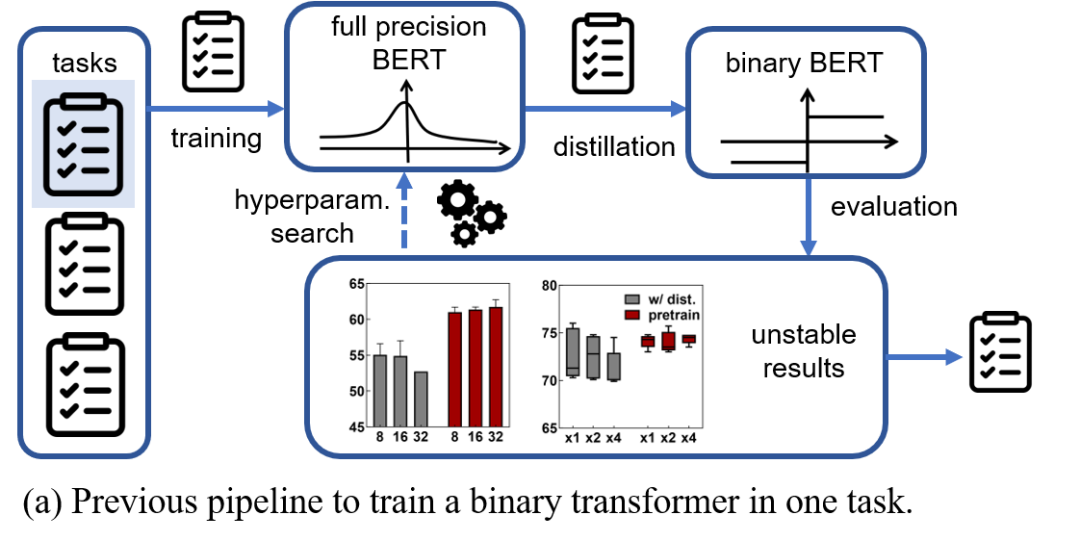

智源团队提出了一种名为BiPFT的1bit轻量化预训练模型,用于自然语言理解任务。与标准的FP32模型相比,BiPFT在推理阶段节省了56倍的操作数量和28倍的内存。与其他1bit模型相比,BiPFT在学习和泛化能力上有显著提升,并在GLUE标准测试集上表现出更好的性能。此外,BiPFT还通过对自注意力操作的量化误差进行参数化,减少了量化损失。实验结果显示,BiPFT在下游任务的训练中具有更好的独立学习能力和超参数鲁棒性。
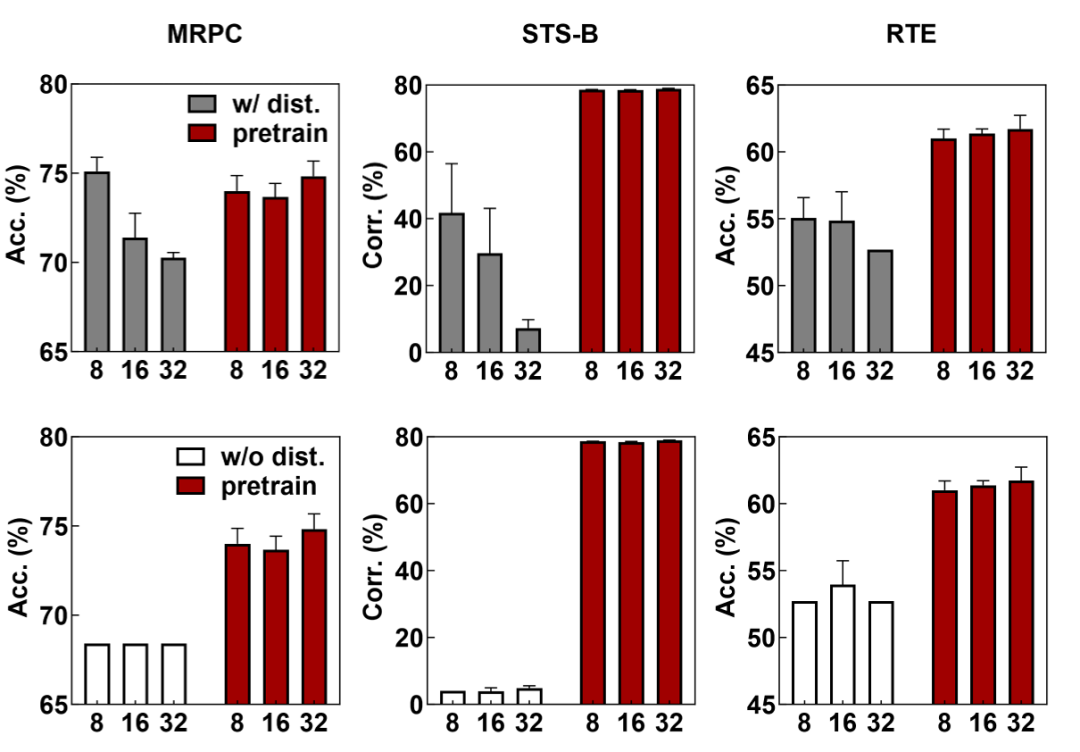
实验结果表明 在各种超参数设定情况下,直接进行1bit预训练的模型BiPFT-A 都能取得更好的效果:
1bit预训练模型BiPFT-A有着较好的独立学习能力:对于直接在下游训练的baseline模型,第一行和第二行的对比说明,baseline模型性能依赖于全精度教师模型的蒸馏。BiPFT-A在下游任务中,不需要教师模型进行蒸馏即可获得更好的效果。
1bit预训练模型BiPFT-A有着较好的超参数鲁棒性:使用蒸馏方法的baseline模型收到鲁棒性差,改变批量和学习率大小会显著影响训练效果。BiPFT-A对超参数(例如:训练批量大小,学习率)的变化不敏感,在常规设定下即可获得较好的结果。
论文地址:
https://arxiv.org/abs/2312.08937
本文地址:https://www.163264.com/6093