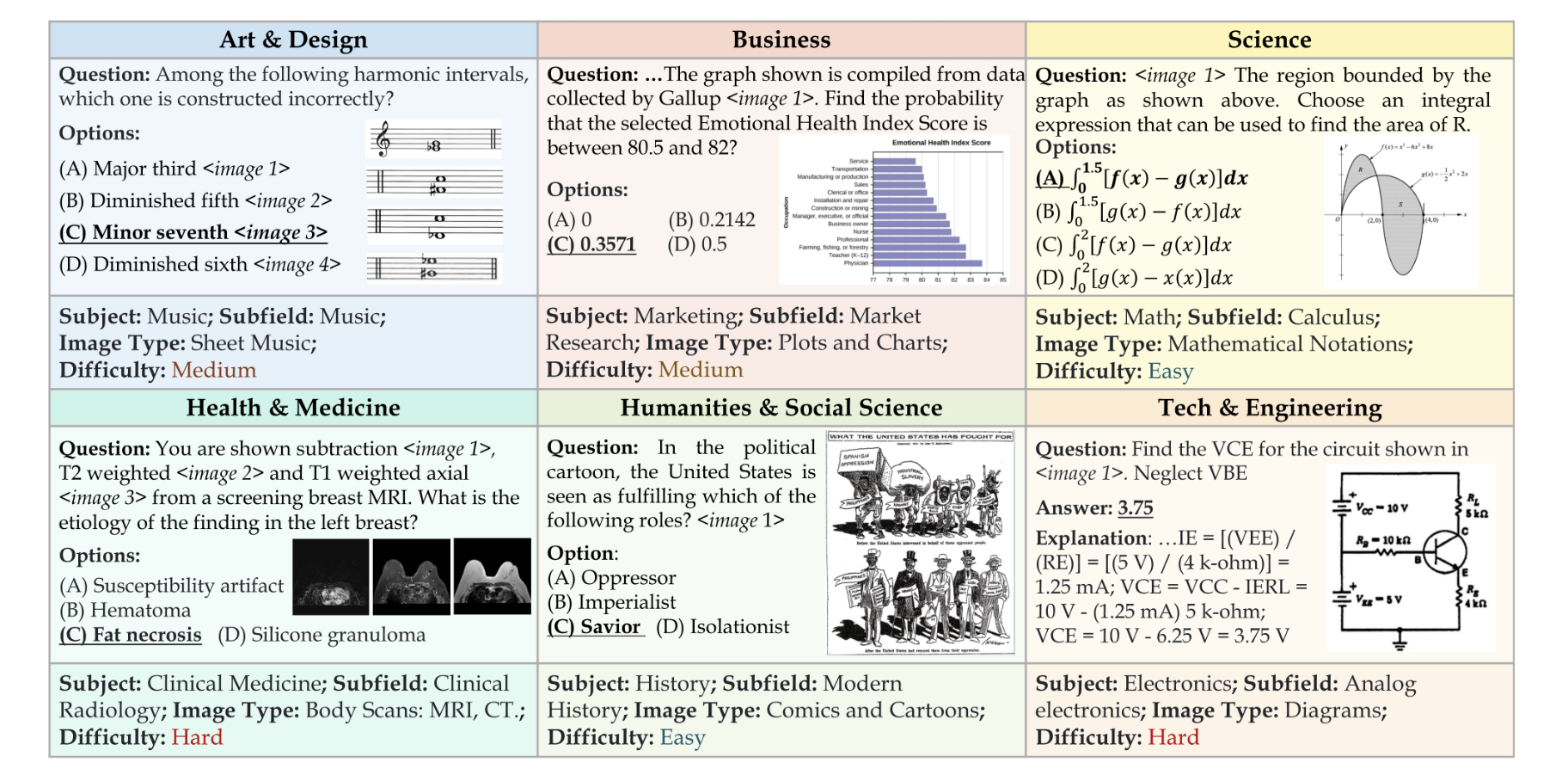

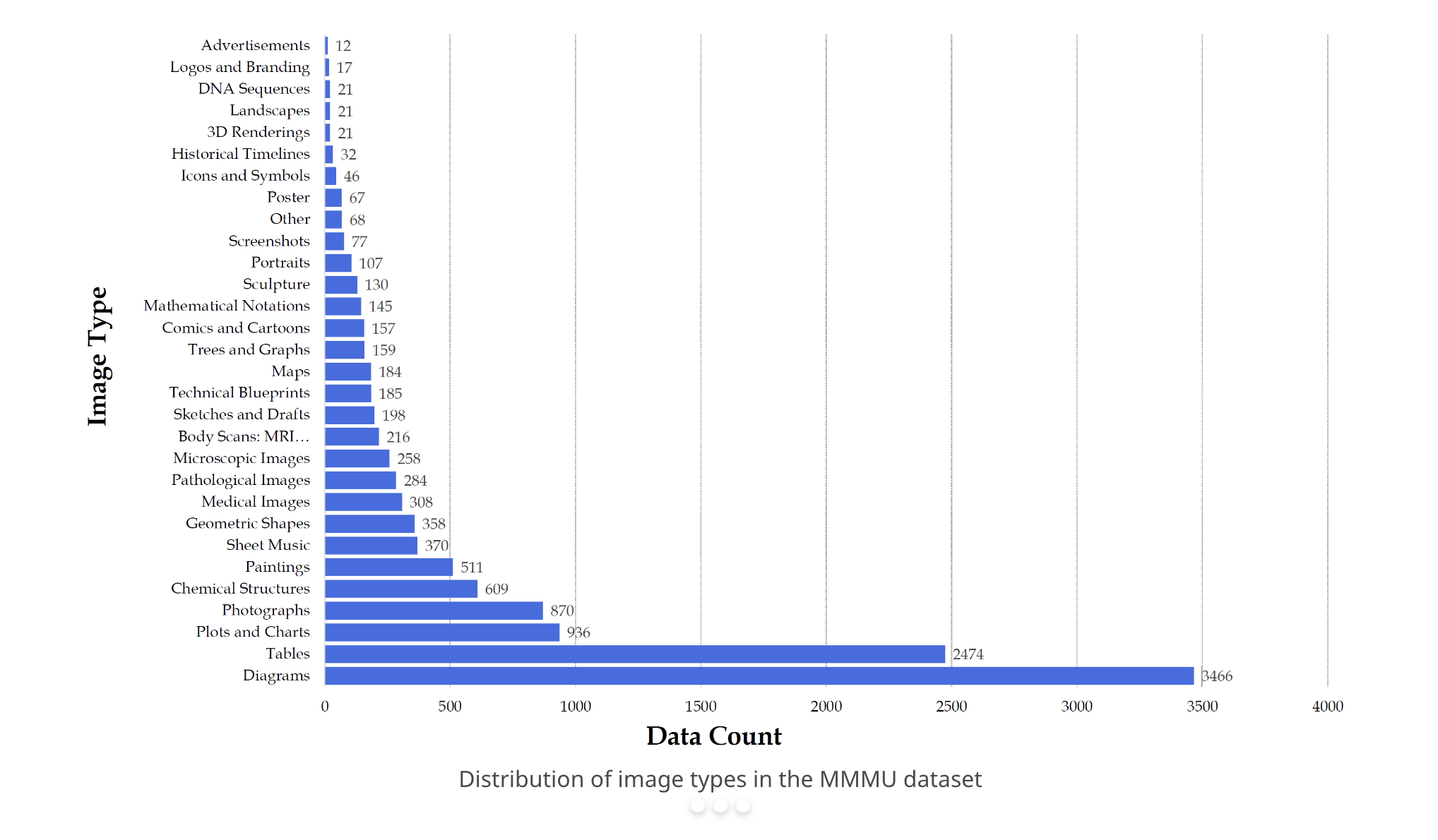
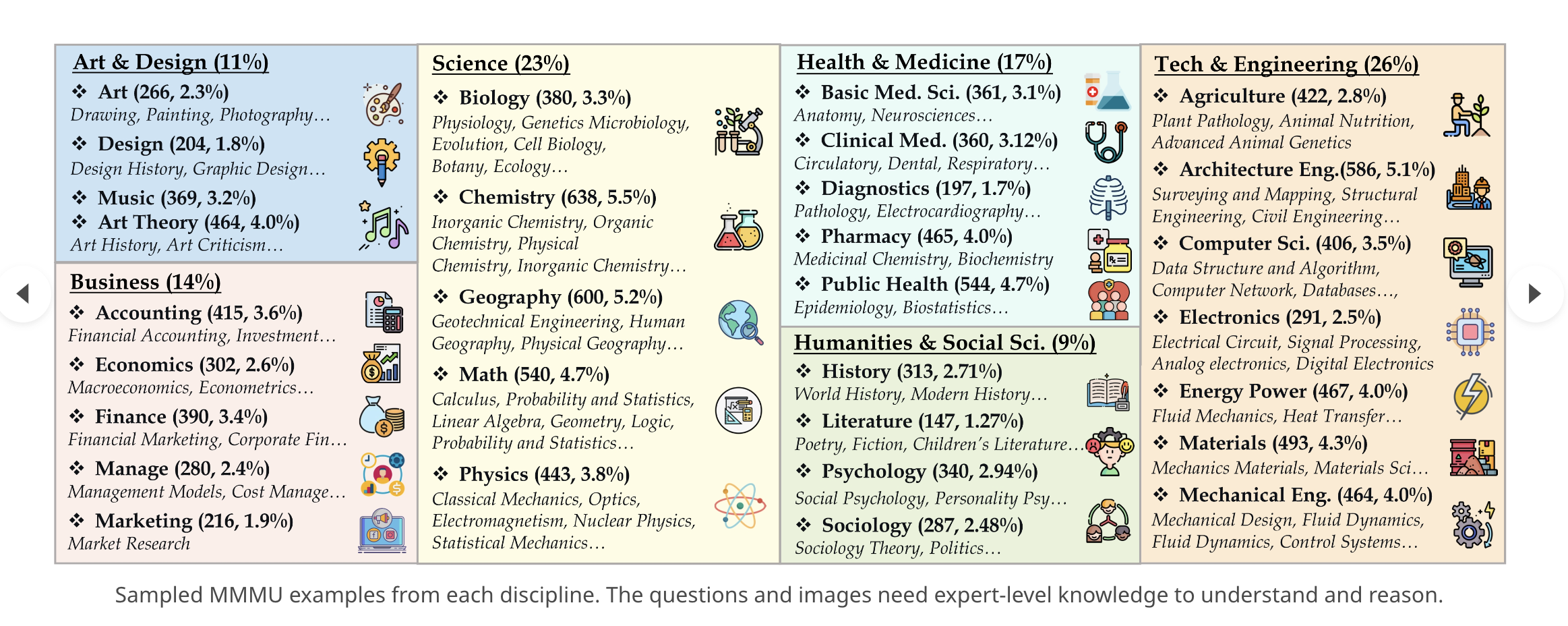
《专家级人工智能的大规模多学科多模态理解和推理基准》是一个新的基准,旨在评估多模态模型在大规模多学科任务上的专家级理解能力。该基准包括来自大学考试、测验和教科书的11500个精心收集的多模态问题,涵盖了艺术与设计、商业、科学、健康与医学、人文与社会科学以及技术与工程等六个核心学科。与现有的基准不同,该基准侧重于具有领域特定知识的高级感知和推理,挑战模型执行类似于专家面临的任务。评估结果显示,即使是先进的GPT-4V模型的准确率也只有56%,还有很大的改进空间。
项目介绍:
https://mmmu-benchmark.github.io/
本文地址:https://www.163264.com/5654