

作者自述:
试图总结这个领域迫使我思考这个领域真正重要的是什么。虽然规模化无疑很突出,但其深远的影响更为微妙。我从三个角度分享我对缩放的想法:
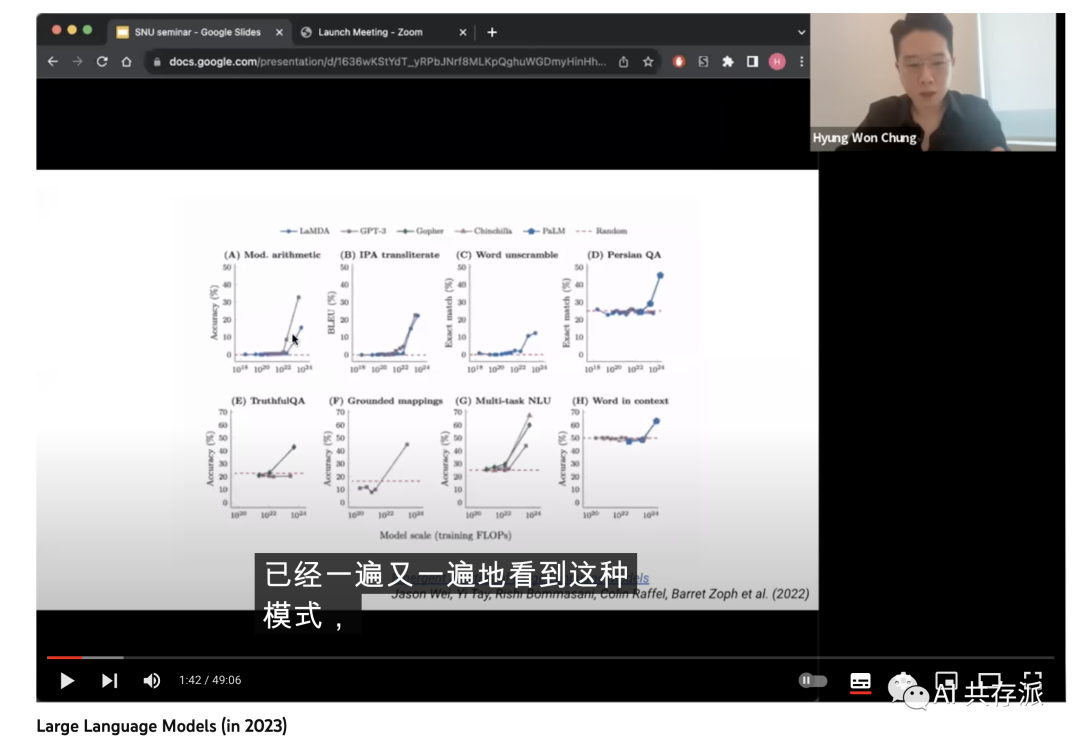
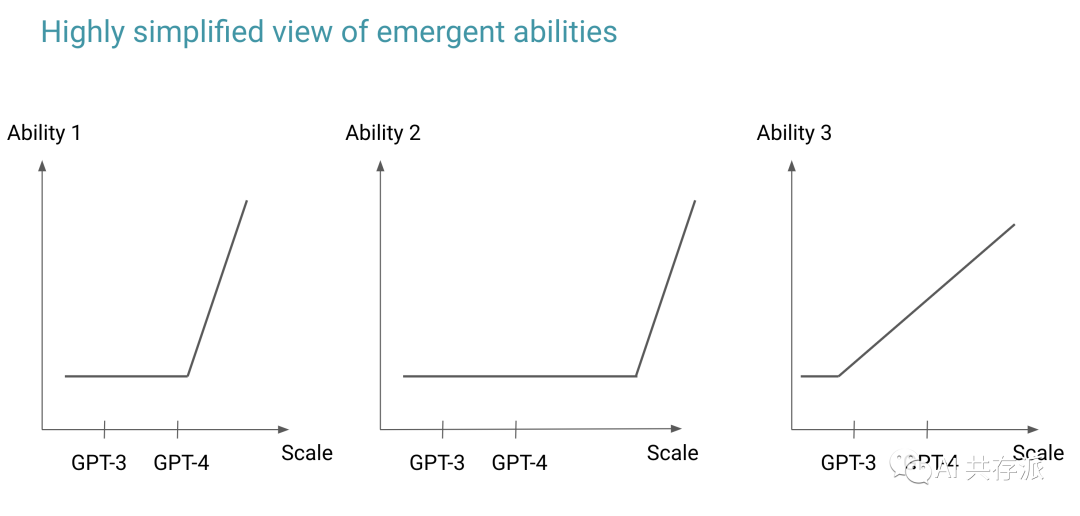
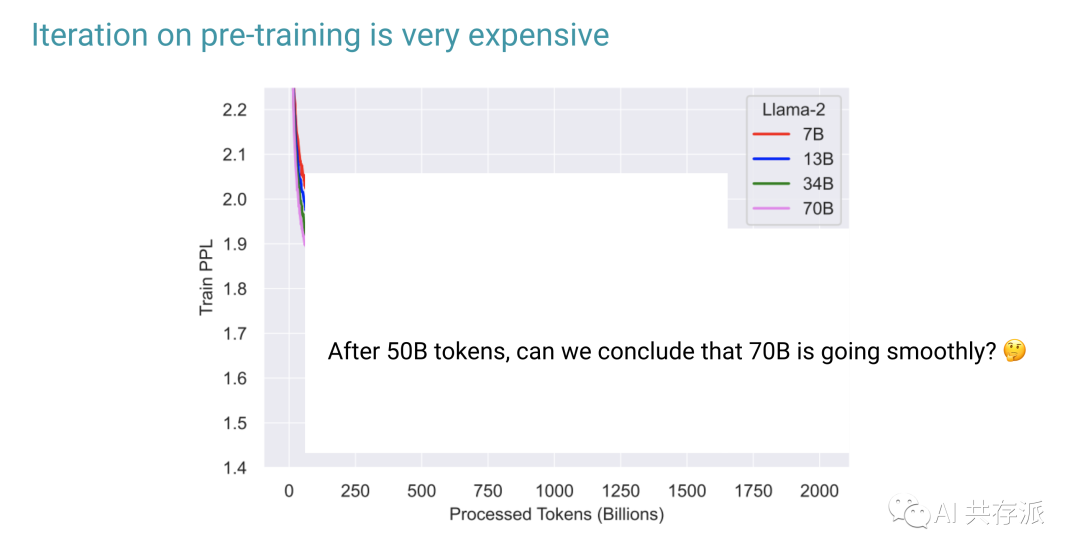
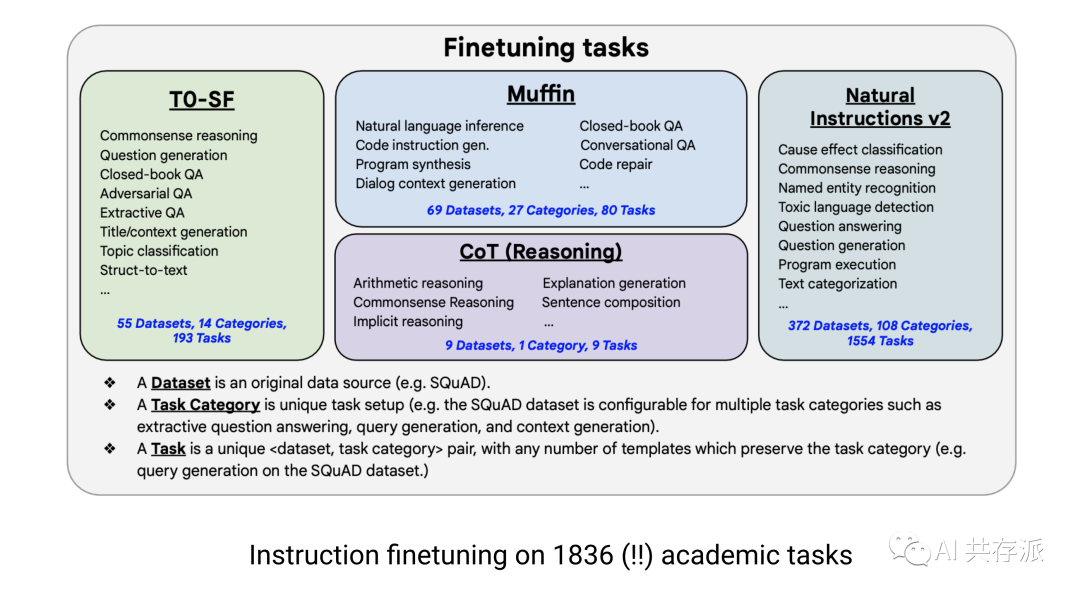
1)改变观点是必要的,因为有些能力只有在一定规模时才会出现。即使某些能力不适用于当前一代的法学硕士,我们也不应该声称它不起作用。相反,我们应该认为它还不起作用。一旦有了更大的模型,许多结论就会改变。
这也意味着过去的一些结论是无效的,我们需要不断地忘记建立在这些想法之上的直觉。
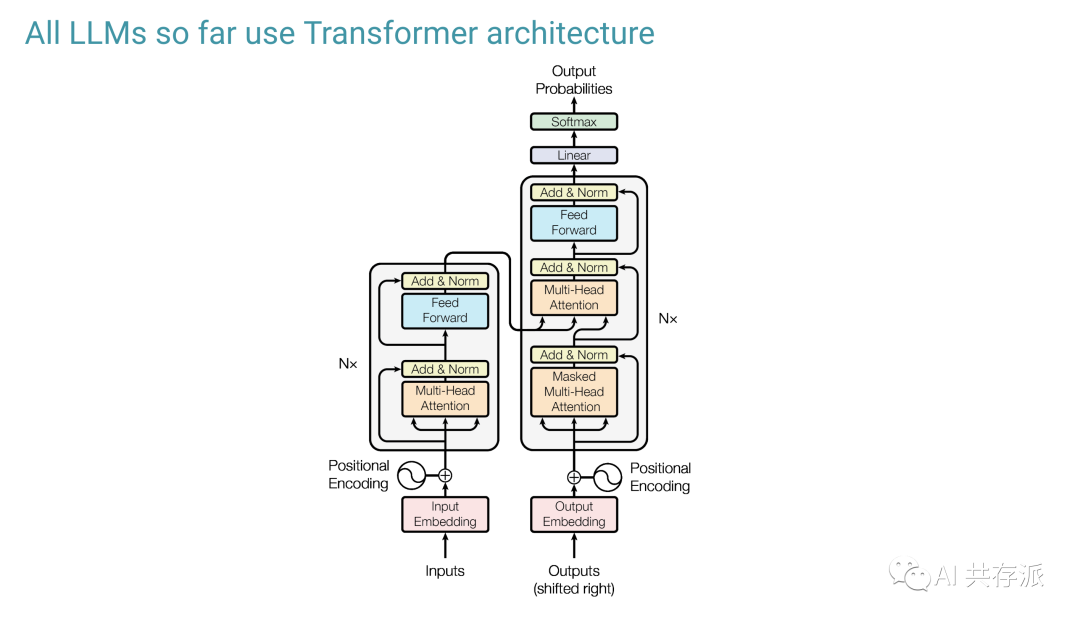
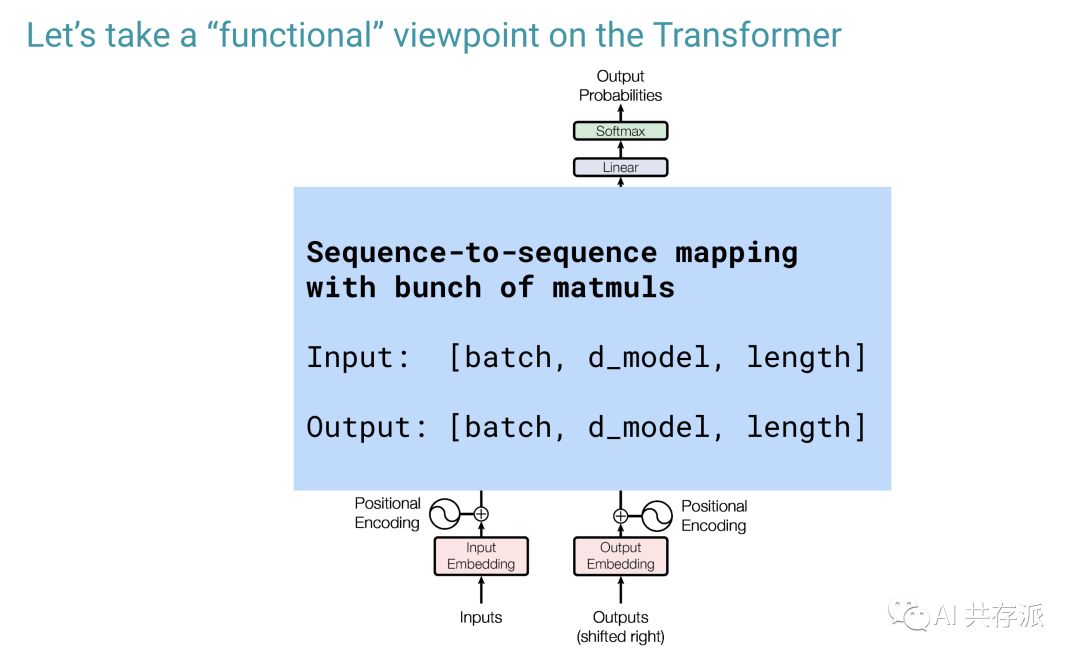
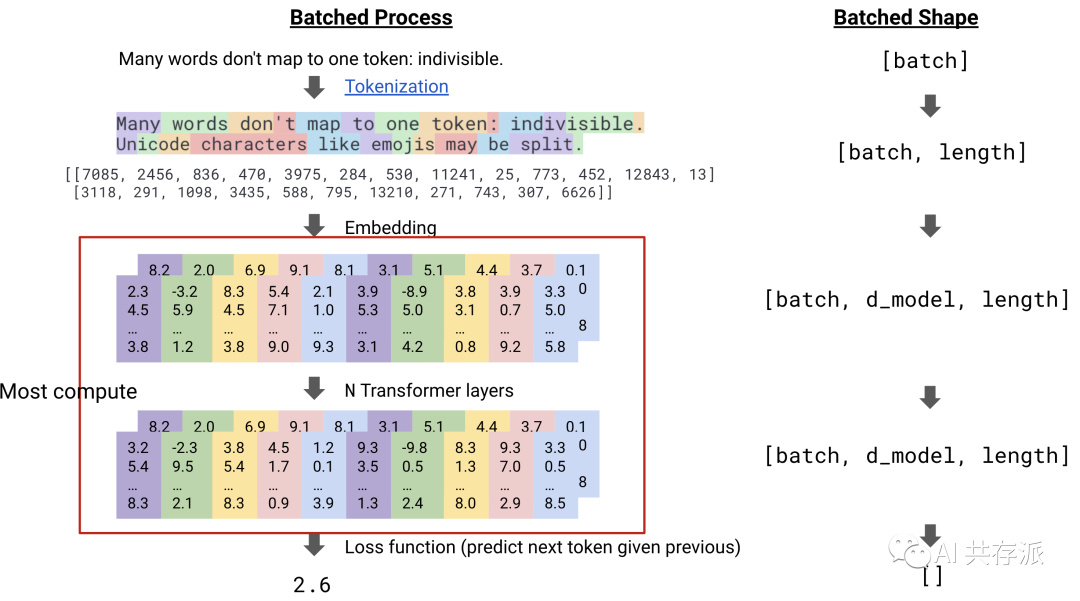
2) 从第一原理来看,扩大 Transformer 的规模相当于用很多很多机器高效地进行矩阵乘法。我看到许多法学硕士领域的研究人员并不熟悉扩展实际上是如何完成的。本节面向想要了解训练大型模型意味着什么的技术受众。
3)我谈论了我们应该考虑进一步扩展的内容(想想 10000x GPT-4 规模)。对我来说,扩展不仅仅是用更多的机器做同样的事情。它需要找到归纳偏差,这是进一步扩展的瓶颈。
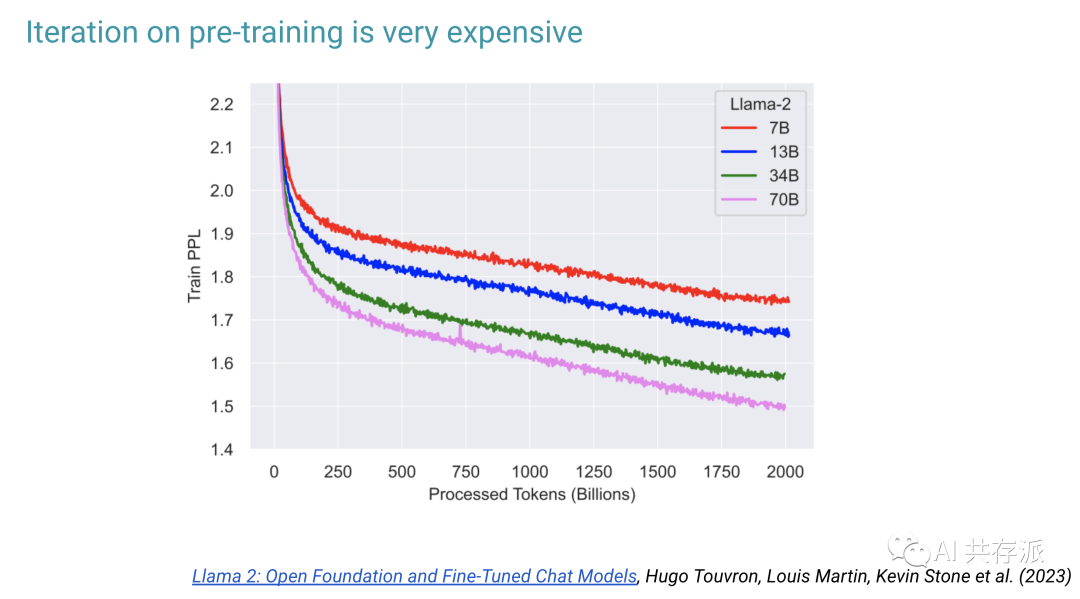
我认为最大似然目标函数是实现 10000x GPT-4 级别规模的瓶颈。使用表达神经网络学习目标函数是下一个更具可扩展性的范式。随着计算成本呈指数下降,可扩展的方法最终获胜。不要与此竞争。
在所有这些部分中,我努力从第一原理出发描述一切。在法学硕士这样一个发展极其迅速的领域,没有人能跟上。我相信,通过第一原理来理解核心思想是唯一可扩展的方法。
ppt地址:
https://t.co/IidLe4JfrC
or
https://t.zsxq.com/13XbHHa9h

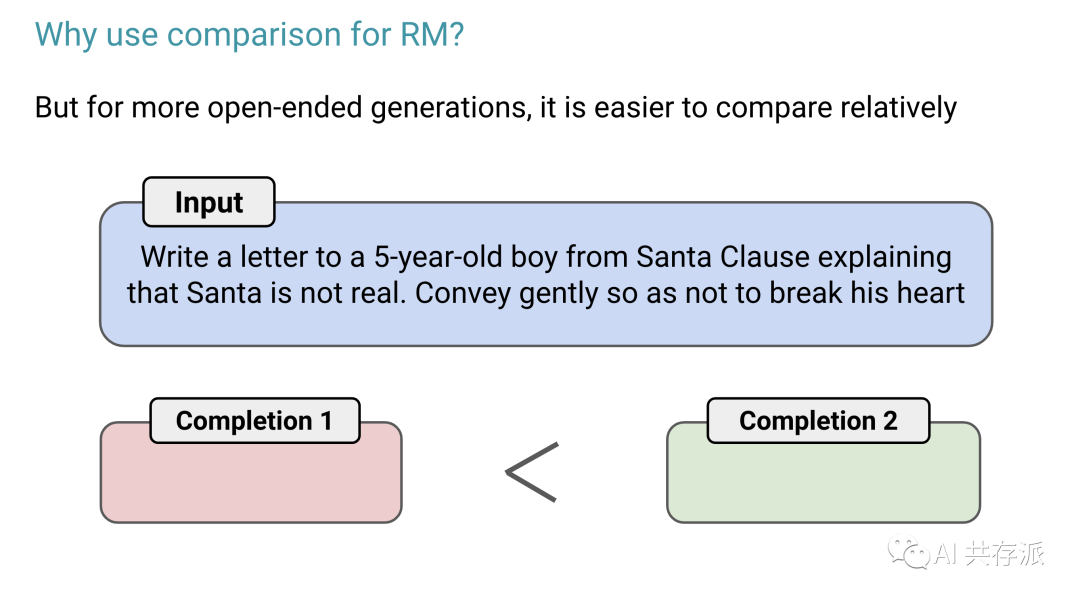
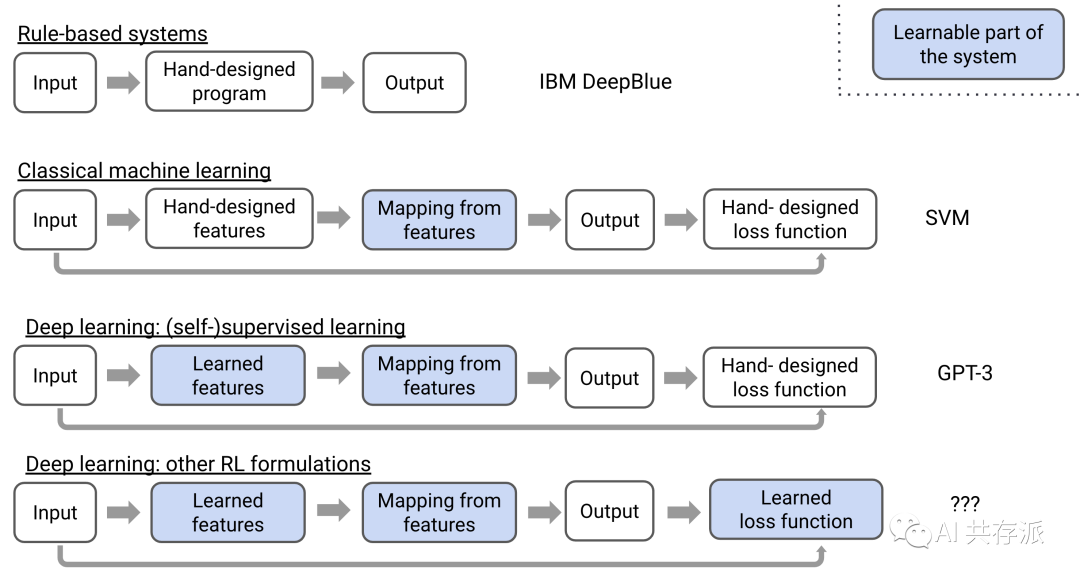
来源:https://mp.weixin.qq.com/s/KcZyvZGOpBsCpc_1ZfUcDg
本文地址:https://www.163264.com/5445