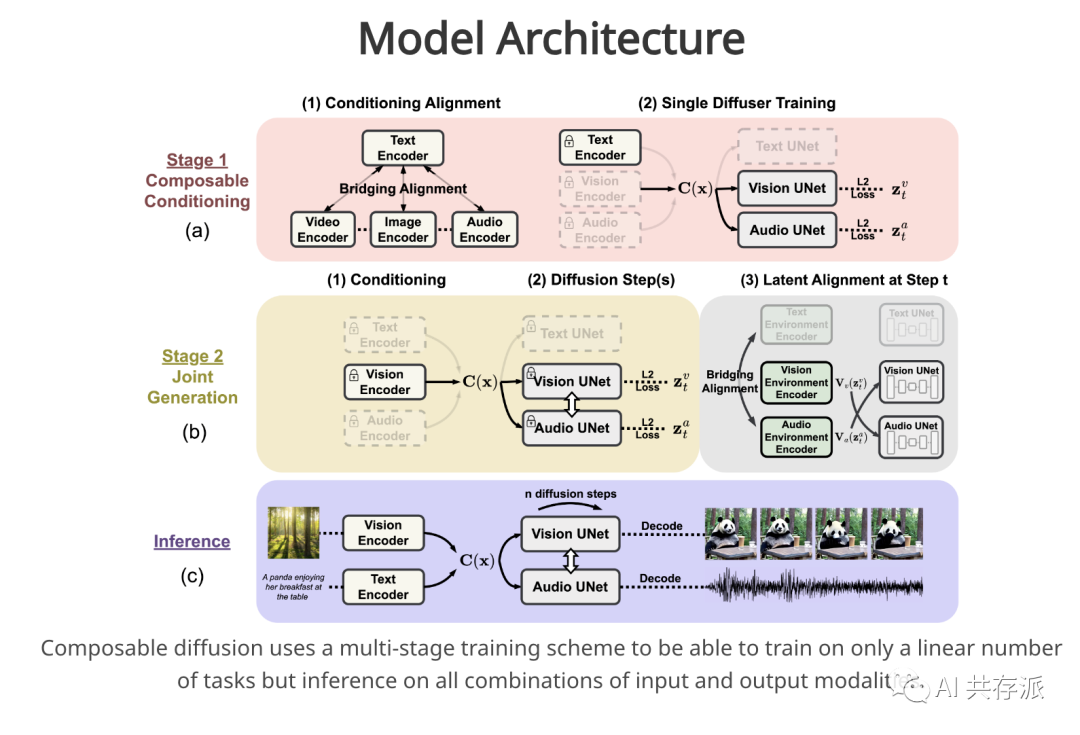

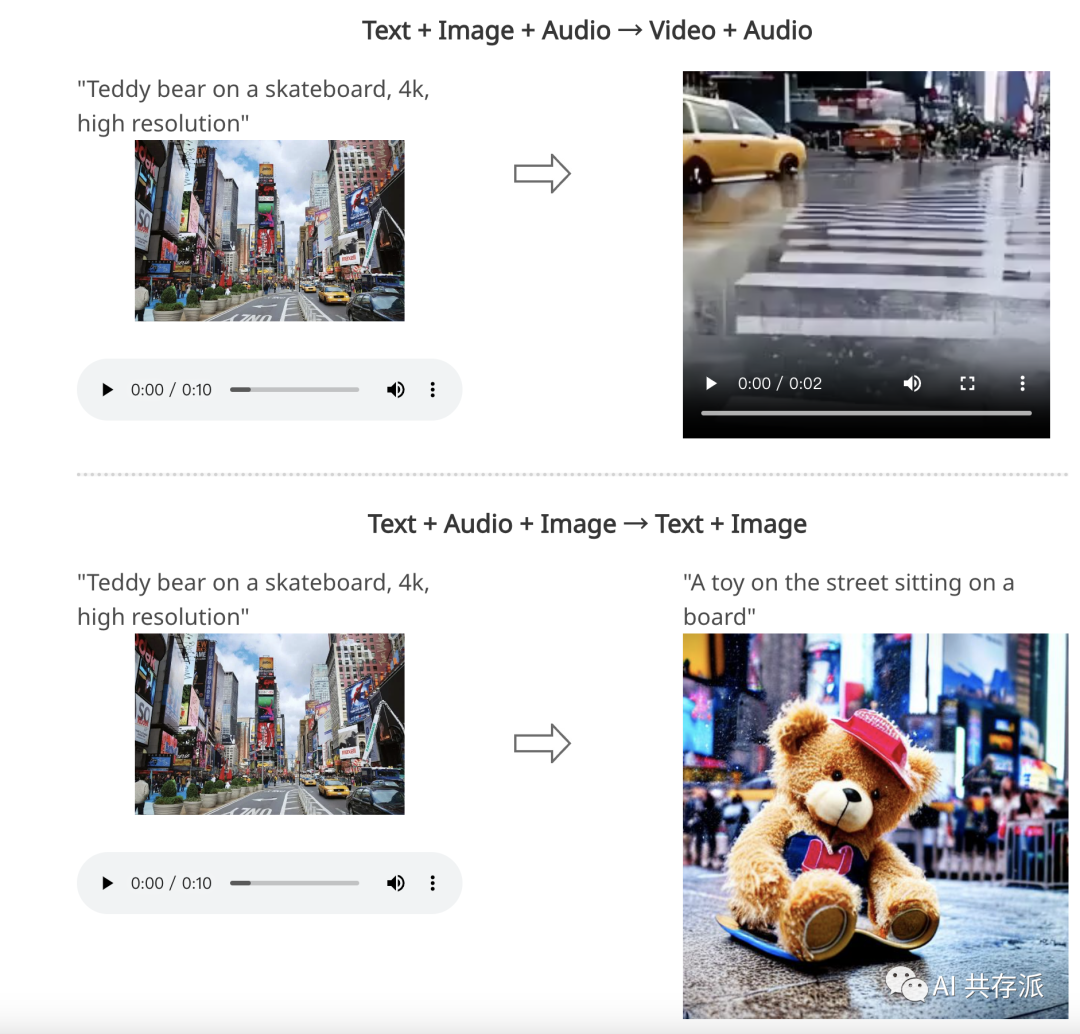
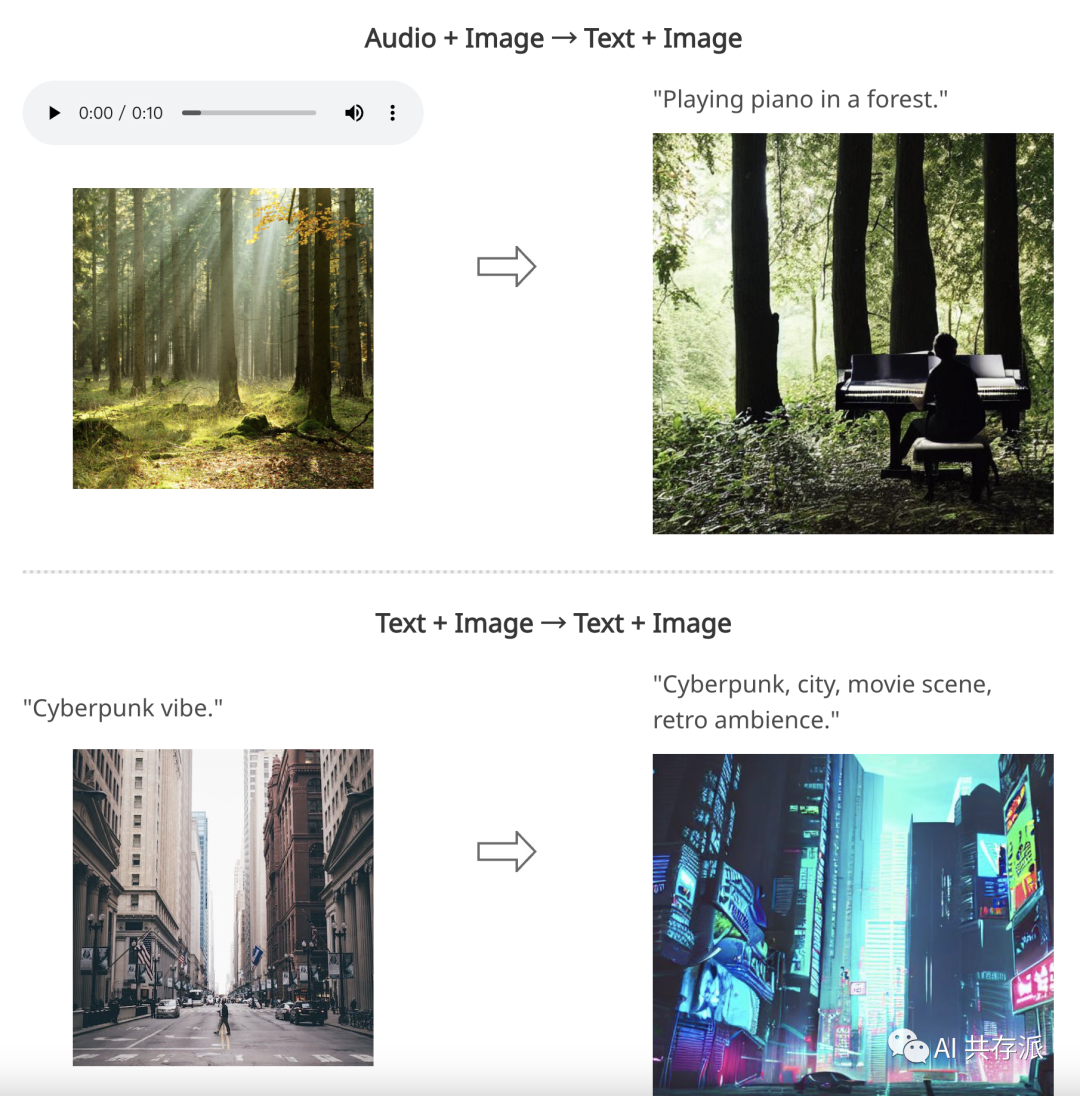
内容:北卡罗来纳大学教堂山分校和微软Azure认知服务研究团队在微软实习期间开发了一种名为Composable Diffusion (CoDi)的创新生成模型。CoDi能够从任何组合的输入模态(如语言、图像、视频或音频)生成任何组合的输出模态。CoDi的输入不仅限于文本或图像,它可以并行生成多种模态。尽管许多模态组合的训练数据集不存在,但我们提出在输入和输出空间内对模态进行对齐。这使得CoDi可以自由地根据任何输入组合进行条件设置,并生成任何模态组,即使它们在训练数据中不存在。CoDi采用了一种新颖的可组合生成策略,通过在扩散过程中进行对齐来构建一个共享的多模态空间,实现了例如时间对齐的视频和音频等交织模态的同步生成。CoDi具有高度定制性和灵活性,实现了强大的联合模态生成质量,并在单一模态合成方面达到或超过了单模态的最新水平。
项目地址:
https://codi-gen.github.io/
来源:https://mp.weixin.qq.com/s/W883fI551E7m0OXgn9hATA
本文地址:https://www.163264.com/5324