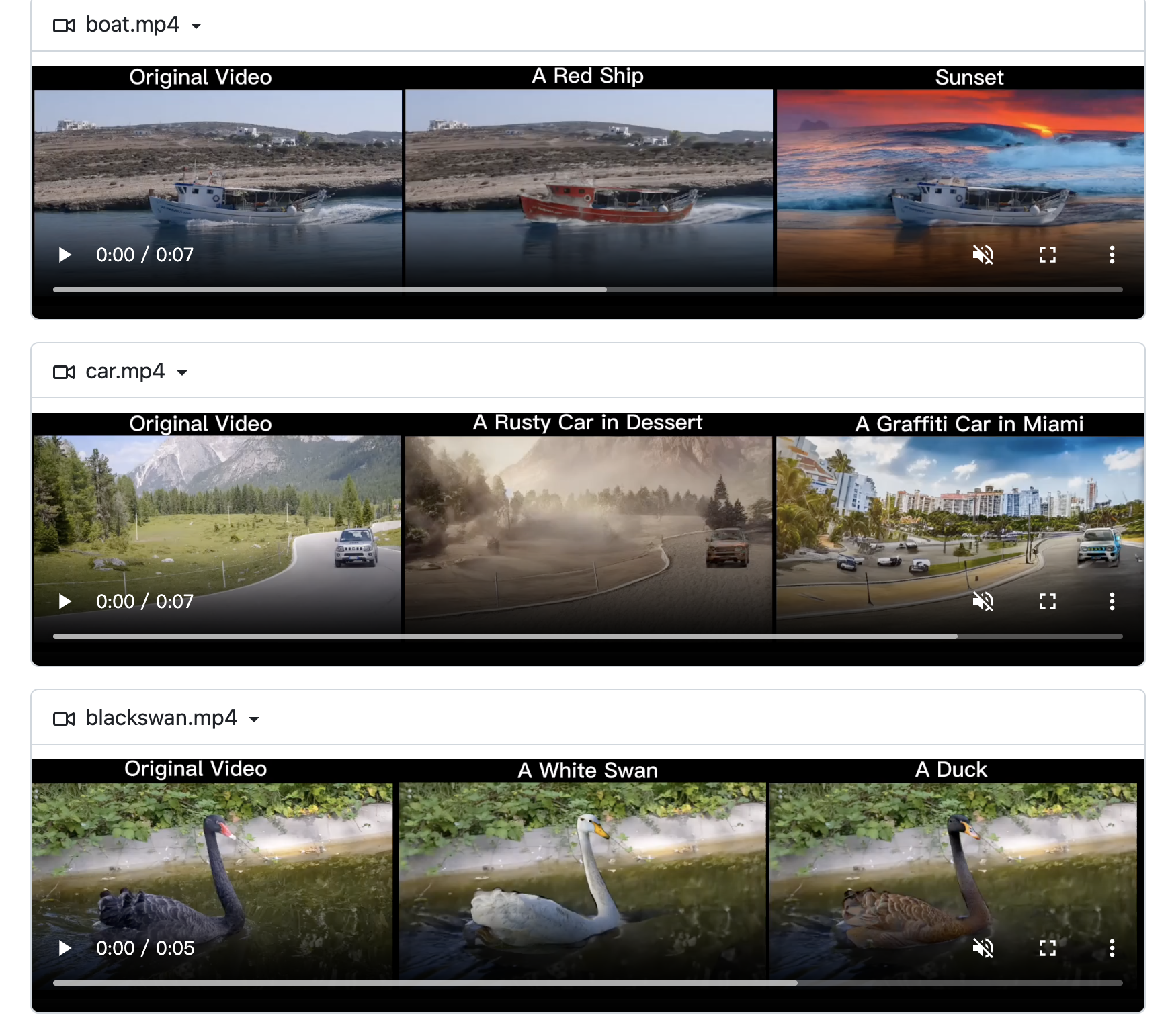

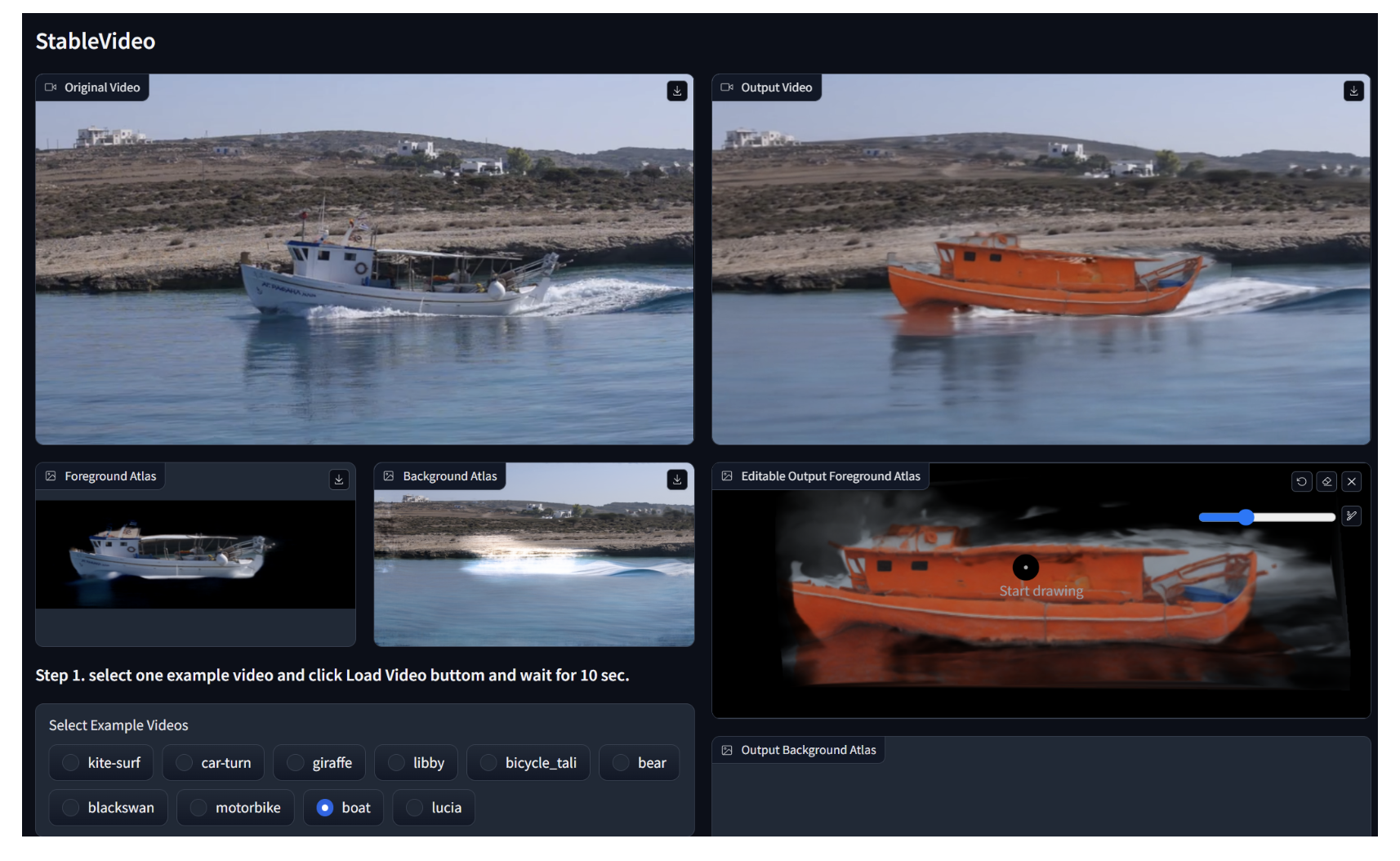
这篇内容介绍了一个基于Diffusion的视频生成模型StableVideo。该模型通过引入时间依赖性,为编辑的对象生成一致的外观,解决了闪烁问题。通过层次表示的概念将外观信息传播到下一帧,构建了一个基于文本的视频编辑框架,可以实现一致性感知的视频编辑。演示视频的合集展示了模型的稳定性,对此感兴趣的人可以下载模型进行尝试。
项目地址:
https://github.com/rese1f/stablevideo
本文地址:https://www.163264.com/5049
这篇内容介绍了一个基于Diffusion的视频生成模型StableVideo。该模型通过引入时间依赖性,为编辑的对象生成一致的外观,解决了闪烁问题。通过层次表示的概念将外观信息传播到下一帧,构建了一个基于文本的视频编辑框架,可以实现一致性感知的视频编辑。演示视频的合集展示了模型的稳定性,对此感兴趣的人可以下载模型进行尝试。
项目地址:
https://github.com/rese1f/stablevideo
本文地址:https://www.163264.com/5049