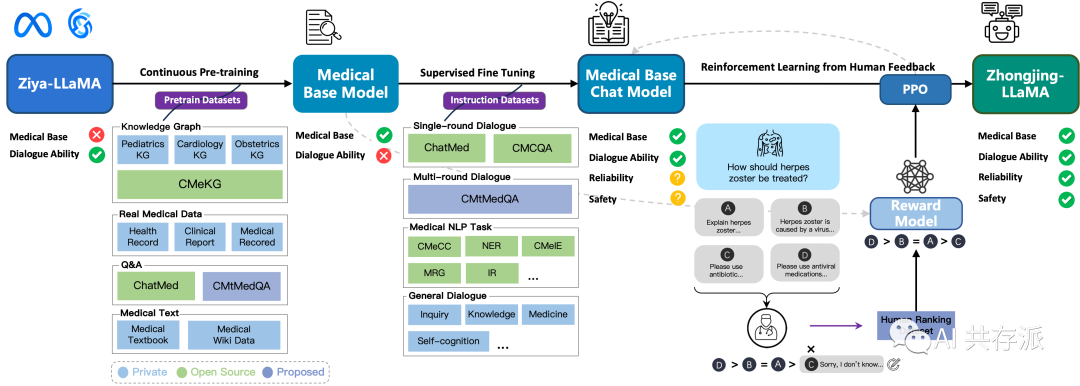

首个实现从预训练到 RLHF 全流程训练的中文医疗大模型。据称某些场景接近专业医生水平。
地址:
https://github.com/SupritYoung/Zhongjing
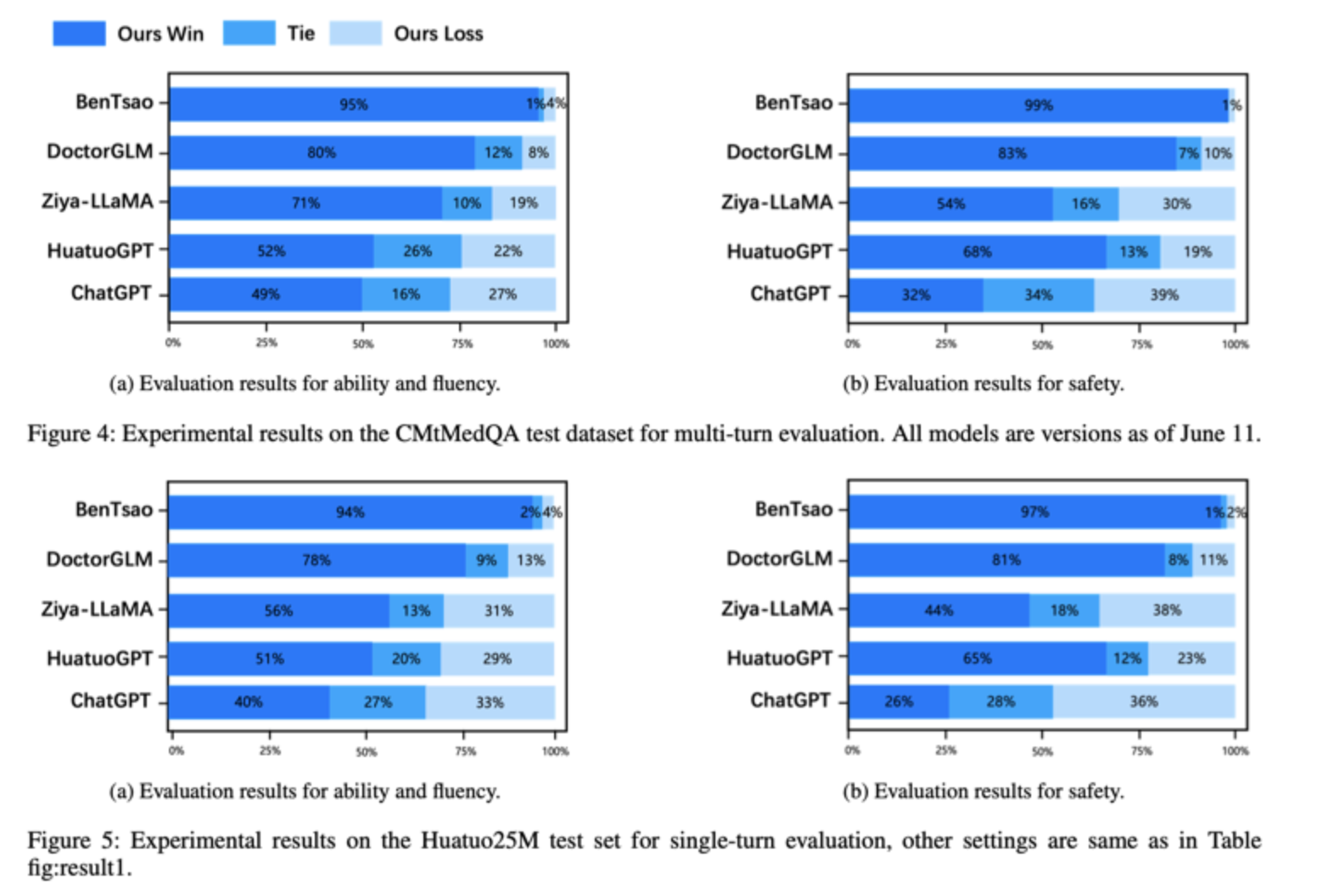
最近,以 ChatGPT 为代表的大型语言模型在许多领域取得了令人瞩目的表现。然而,由于医学等领域的复杂性和专业性,这些模型在特定领域(如医学)的表现相对较差。虽然一些中文医学大型模型已经出现,但它们主要是在质量参差不齐的单轮医疗对话上微调基础模型,导致改进有限。 Zhongjing-LLaMA 是首个实现了预训练、有监督微调和强化学习与人类反馈(RLHF)完整训练流程的中文医学大型模型的,展现出了很好的泛化能力,在某些对话场景中甚至接近专业医生的专业水平。 此外,我们精心构建了一个包含 70,000 条完全来源于真实医患对话的多轮对话数据集。该数据集包含大量医生主动提问的语句,有助于提升模型的主动医疗询问能力。
本文地址:https://www.163264.com/4886