

项目介绍:
https://animatediff.github.io/
代码:
https://github.com/guoyww/animatediff/
论文:
https://arxiv.org/abs/2307.04725
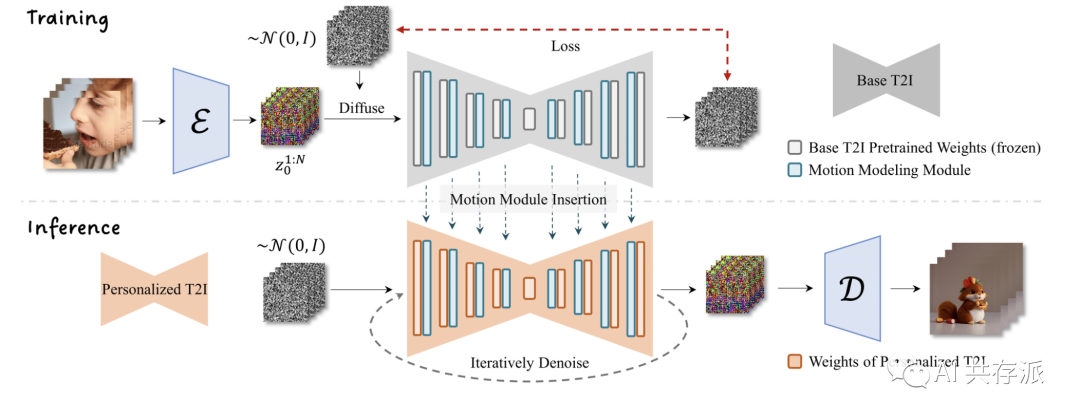
– 文本到图像模型和个性化技术的进步使得每个人都能以较低的成本将他们的想象力体现为高质量的图像。

– 存在对图像动画技术的需求,以进一步将生成的静态图像与动态运动结合起来。

– 该项目提出了一个有效的框架,可以一次性为大多数现有的个性化文本到图像模型提供动画效果,节省了模型特定调整的工作。

– 提出的框架的核心是将一个新初始化的运动建模模块附加到冻结的基于文本到图像模型上,并在此后的视频剪辑中对其进行训练,以提取合理的运动先验知识。
– 一旦训练完成,通过简单地注入这个运动建模模块,所有从相同基础模型派生的个性化版本都能够产生多样化和个性化的动画图像。
– 在画廊中展示了使用我们框架中注入了运动建模模块的模型生成的最高质量的动画。点击播放下面的动画。
– 展示了使用相同提示和相同模型的结果,证明我们的方法不会破坏原始模型的多样性。点击播放下面的动画。
AI商业赋能实验室:Ai+Tee,Ai写真,Ai头像,Ai老照片修复
来源:https://mp.weixin.qq.com/s/d477Y_F4yFYVtQpgyNYDew
本文地址:https://www.163264.com/4536