西风 发自 凹非寺
量子位 | 公众号 QbitAI
作为最权威的科学期刊之一,Nature近日明确表态:
禁止使用生成式人工智能(AIGC)创作的图像和视频内容!
这也就意味着,除了主题是讨论AI的文章,任何Nature接收的作品须确保无任何AIGC生成或增强的视觉内容。
这张反对票上写满了一行大字:
诚信、许可、隐私和知识产权保护


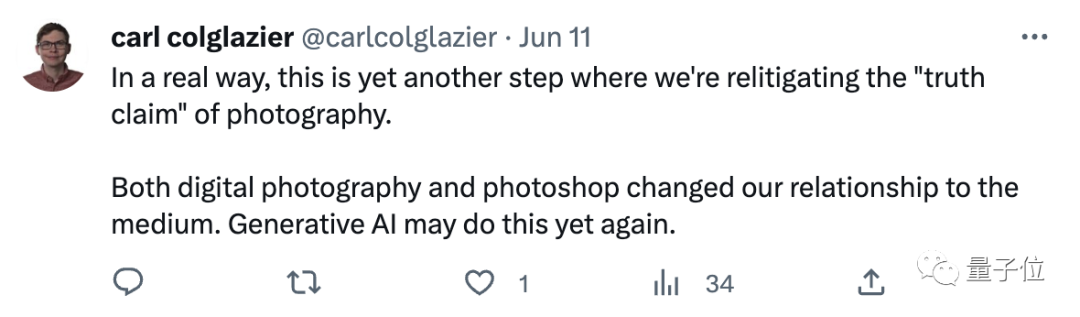
有网友认为:
实际上,这是我们重新讨论摄影“真相主张”,所迈出的新的一步。
数码摄影和Photoshop都改变了我们与媒体的关系,而AIGC可能会再次做到这一点。
ChatGPT爆火,一举推动AIGC强势“出圈”,各行各业都在争相探索其潜力。然而,在科学、艺术、出版等领域,对于是否允许在视觉内容中使用AIGC的争议从未停歇。
对AIGC的担忧,与近半年来AIGC使用不规范所造成的侵权现象加剧密不可分。
早在今年一月份,在美国加州北区法院,就有三名漫画家针对包括Stability AI在内的三家AIGC商业应用公司发起集体诉讼,指控Stable Diffusion侵权,类似案件屡见不鲜。
上个月,当下最热门的短视频社交平台之一——抖音,提出了十一条平台规范与行业倡议:
创作者、主播、用户、商家、广告主等平台生态参与者,在抖音应用生成式人工智能技术时,需遵循十一条规范。
其中就包括对AIGC生成的内容进行显著标识,禁止利用AIGC技术创作、发布侵权内容以及违背科学常识、弄虚作假、造谣传谣的内容。
而已有153年历史的Nature,对待AIGC只有一个简单的“不”字。
Nature为什么要禁用AIGC?
在诸如ChatGPT、Midjourney等生成式AI工具得到广泛应用,且能力快速增长之后,Nature坐不住了。
针对此问题已经进行了几个月的激烈讨论和磋商。

最终的结果是:
除非是专门关于人工智能的文章,Nature在可预见的未来不会发表任何完全或部分使用AIGC创作的摄影、视频或插图内容。
Nature将不允许在视觉内容中使用AIGC,原因归结为:
诚信问题。
无论是科学还是艺术创作,在出版过程中,都应以共同的诚信承诺为基础。
其中之一,就是保持过程透明。
研究人员、编辑和出版商都应该明确数据和图像来源,保持其准确性和真实性。而这是现有AIGC工具所无法做到的。
AIGC工具不提供访问数据和图像来源的方式,因此无法进行这种验证。
还有一大难题是归属问题。
当使用或引用现有作品时,准确标注来源的重要性不可忽视,这也是科学和艺术出版领域的一大核心原则。
显然AIGC工具生成的内容无法明确归属权的问题。
同意和许可也是必须要考虑的因素之一。
如果牵涉到有知识产权的内容,必须获得同意和许可,而AIGC在这一问题上再次未能达到期望。
AIGC系统是在未识别来源的图像上进行训练的。一些受版权保护的作品,常常没有进行许可,就被用于训练AIGC。在某些情况下,还会侵犯隐私权,例如未经同意使用他人照片或视频。
除了隐私问题外,这些经过“深度伪造”的内容还容易加速虚假信息的传播。
One More Thing
Nature虽然对AIGC生成的视觉内容不予采用,但允许文本中包含通过AIGC辅助生成的内容。
前提是遵循一些注意事项:
使用这类大语言模型(LLM)工具需要在论文的研究方法或致谢部分进行记录,并且我们期望作者提供所有数据的来源,包括辅助人工智能生成的数据。此外,任何LLM工具都不会被接受为论文作者。
Nature认为这样做是为了保护内容创作成果。世界正处于人工智能革命的边缘,这场革命带来了巨大的希望,但也在迅速颠覆科学、艺术、出版等长期确立的传统。在使用AI时稍不注意,就有可能使经历了数个世纪的发展所形成的保护科学诚信和保护内容创作者免受剥削的体系瓦解。
对此,你怎么看?
参考链接:
[1]https://www.nature.com/articles/d41586-023-01546-4
[2]https://arstechnica.com/information-technology/2023/06/nature-bans-ai-generated-art-from-its-153-year-old-science-journal/
— 完 —
线下嗨聊 AIGC两整天,稀土开发者大会来袭!
超值199元门票限量抢购中,转发海报有机会赢免费参会!
北京大学王选计算机研究所教授、CCF 自然语言处理专委会秘书长万小军确认出席主论坛,来自字节跳动、腾讯、虾皮、Intel、Google等公司的技术嘉宾,将带来一整天的「大模型与AIGC 」分论坛。
6月30日-7月1日,北京见!扫码报名还可参与抽奖,扫海报二维码或点击阅读原文即可报名:

来源:https://mp.weixin.qq.com/s/7w1K1DZEYmXAK6bRnQ8l7A
本文地址:https://www.163264.com/4216