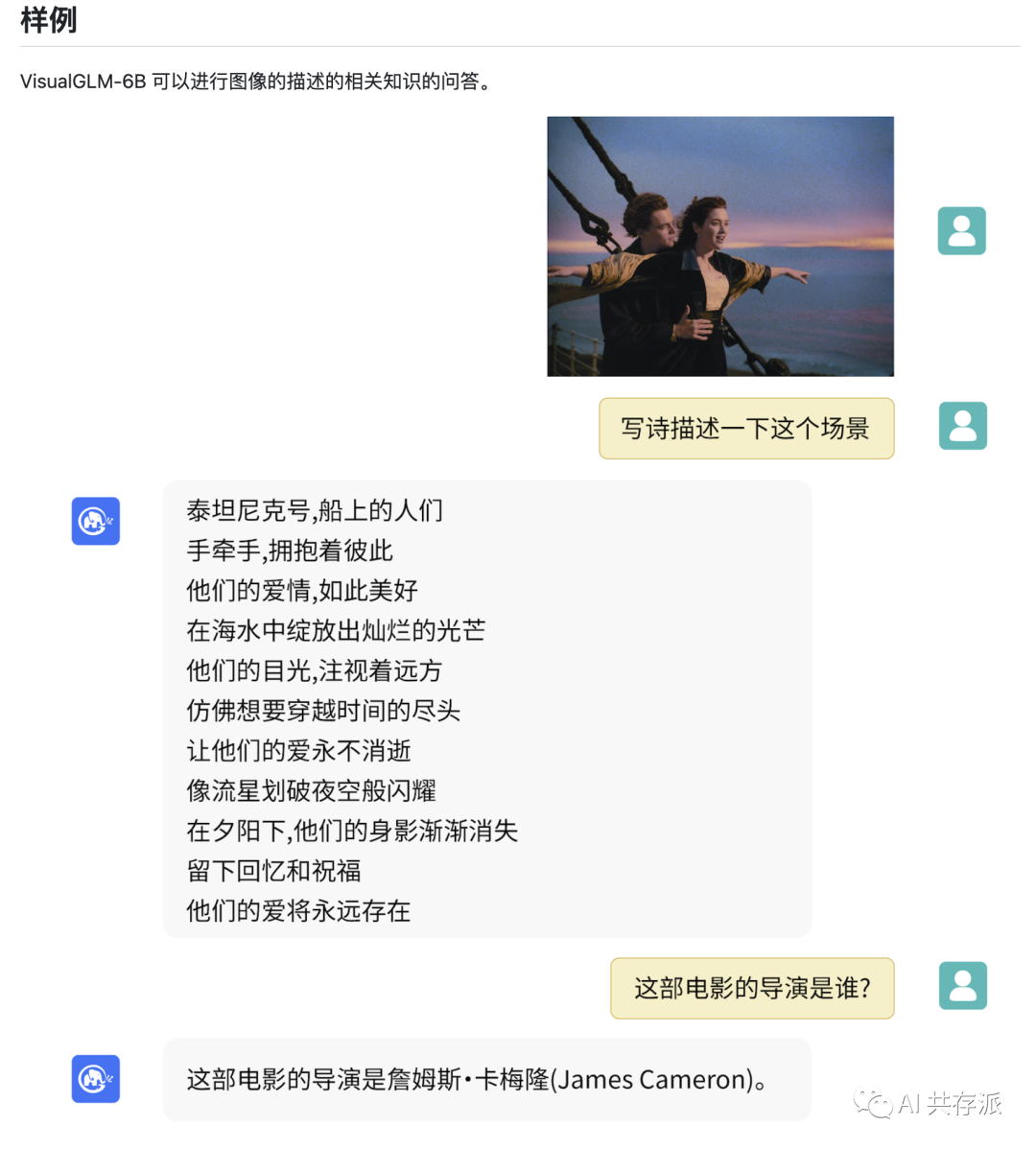
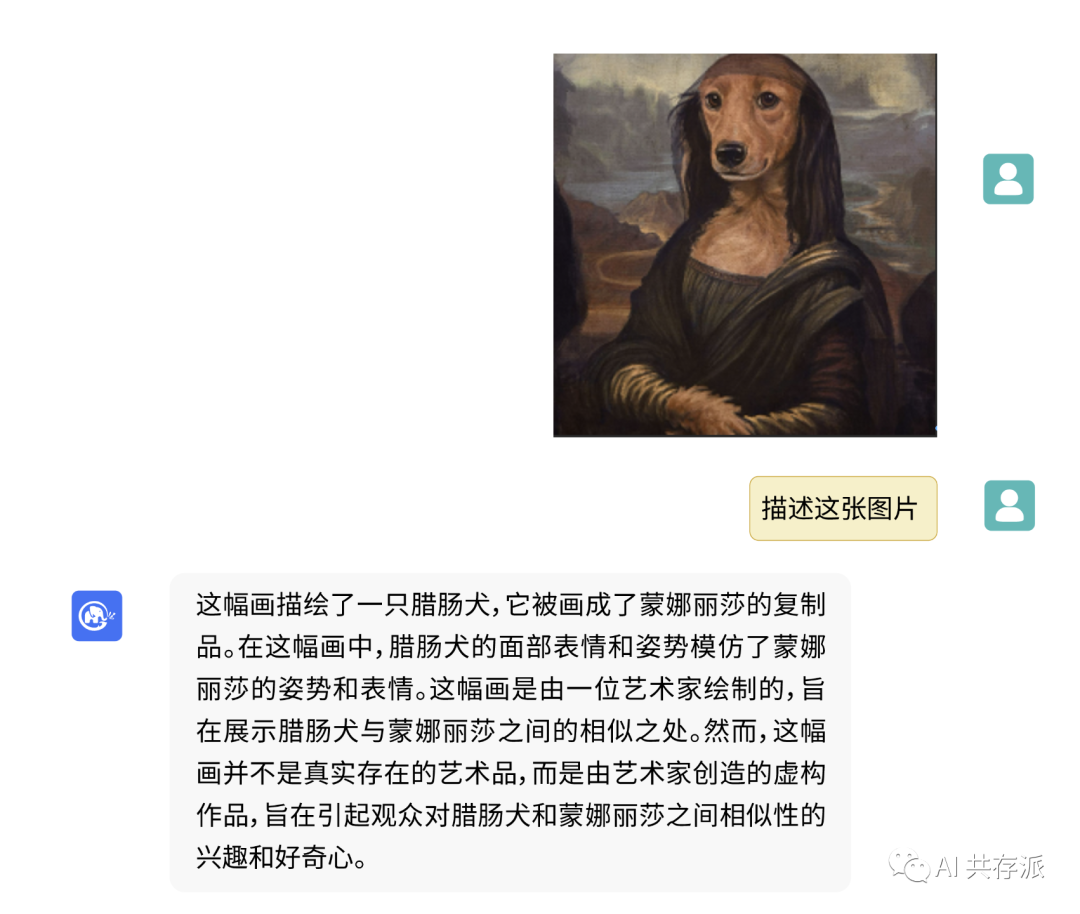
清华大学与智谱AI合作开发的中文开源大模型VisualGLM-6B可以解读表情包,并且已经推出了网页端试玩版。该模型主要用于中文图像理解,可解读图片场景、物品名称等信息,但对于含有文字的表情包却无法理解。VisualGLM-6B是以ChatGLM-6B为基础进行开发的,支持中英双语对话,已经在GitHub上发布,引起广泛关注。
可以将图片经由AI视觉处理,输出对图片的文本描述。
项目地址:
https://github.com/THUDM/VisualGLM-6B

来源:https://mp.weixin.qq.com/s/vzYPYFab9QQAdoP05w7Nig
本文地址:https://www.163264.com/3466