
Stability AI与其多模态AI研究实验室DeepFloyd联合发布了DeepFloyd IF,这是一种强大的文本到图像级联像素扩散模型。它采用T5-XXL-1.1等大型语言模型作为文本编码器,可将文本描述转换为图像。除了基本的生成图像文本之外,DeepFloyd IF还可以生成非标准宽高比的图像,并可以实现零恢复图像修改,细节和样式重新生成等功能。该模型可以为多个领域如艺术、设计、虚拟现实、可访问性提供新型应用。

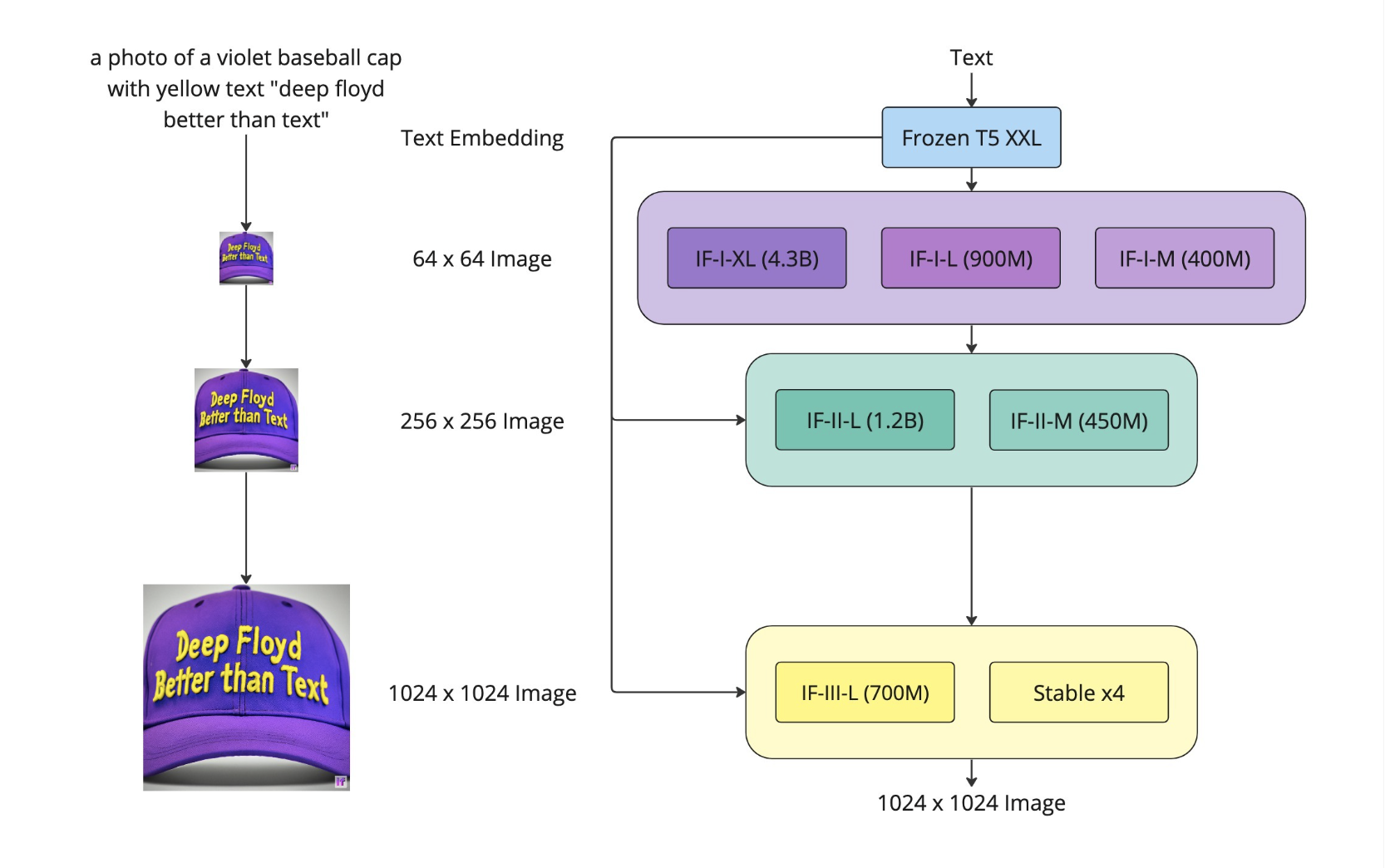
This generation flowchart represents a three-stage performance:
这个世代流程图代表了一个三阶段的表现:
A text prompt is passed through the frozen T5-XXL language model to convert it into a qualitative text representation.
将文本提示通过冻结的T5-XXL语言模型传递,将其转换为定性文本表示。
Stage 1: A base diffusion model transforms the qualitative text into a 64×64 image. This process is as magical as witnessing a vinyl record’s grooves turn into music. The DeepFloyd team has trained three versions of the base model, each with different parameters: IF-I 400M, IF-I 900M and IF-I 4.3B.
阶段1:基础扩散模型将定性文本转换为64×64图像。这个过程就像看到黑胶唱片的凹槽变成音乐一样神奇。DeepFloyd团队已经训练了三个版本的基础模型,每个模型都有不同的参数:IF-I 400M、IF-I 900M和IF-I 4.3B。
Stage 2: To ‘amplify’ the image, two text-conditional super-resolution models (Efficient U-Net) are applied to the output of the base model. The first of these upscales the 64×64 image to a 256×256 image. Again, several versions of this model are available: IF-II 400M and IF-II 1.2B.
第二阶段:为了“放大”图像,将两个文本条件的超分辨率模型(Efficient U-Net)应用于基础模型的输出。其中第一个将64×64的图像放大到256×256的图像。同样,有几个版本的模型可用:IF-II 400M和IF-II 1.2B。
Stage 3: The second super-resolution diffusion model is applied to produce a vivid 1024×1024 image. The final third stage model IF-III has 700M parameters. Note: We have not released this third-stage model yet; however, the modular character of the IF model allows us to use other upscale models – like the Stable Diffusion x4 Upscaler – in the third stage.
第三阶段:应用第二个超分辨扩散模型生成逼真的1024×1024图像。最终的第三阶段模型IF-III具有700M参数。注意:我们尚未发布此第三阶段模型;但是,IF模型的模块化特性允许我们在第三阶段使用其他升级模型,例如稳定扩散x4升频器。
模型介绍:
https://stability.ai/blog/deepfloyd-if-text-to-image-model
git地址:
https://github.com/deep-floyd/IF
模型体验:
https://huggingface.co/spaces/DeepFloyd/IF
模型网站:
https://deepfloyd.ai/deepfloyd-if
本文地址:https://www.163264.com/2902