
英伟达最近发布了一个可以高分辨率生成文本并生成图像的模型。该模型通过对LDM生成的图像进行微调,并添加视频序列帧和时间信息,实现了高分辨率文本生成图像的效果。从演示页面可以看到,生成的图像质量非常好,分辨率甚至可以达到1280 x 2048,而且连续性也非常好。相比Gen-2模型的示例,这款模型看起来要好很多。这是否真的是万物Diffusion的效果?我们拭目以待。
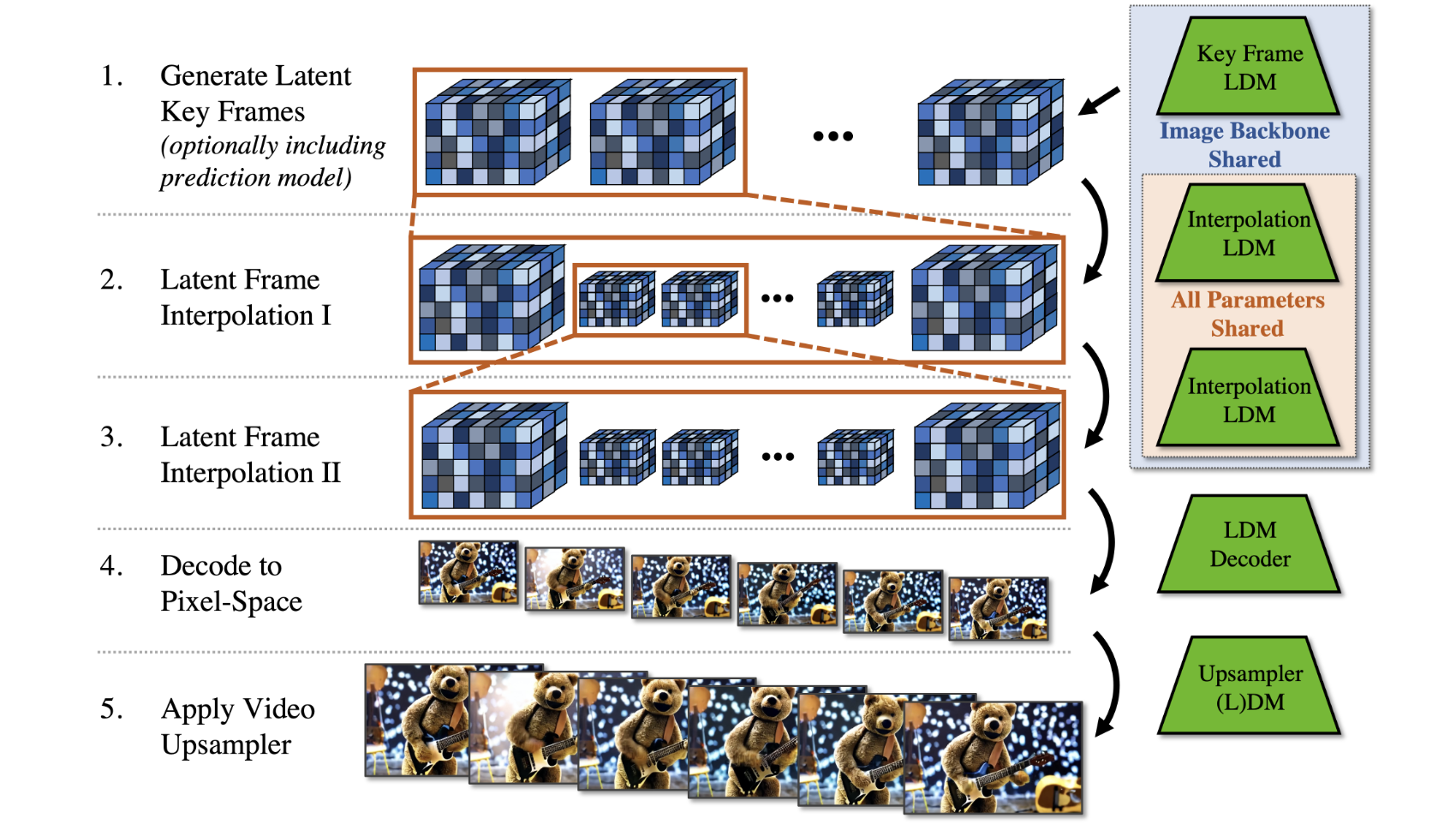
以下是其工作原理的简要概述:
1. 在图像数据集上预训练图像 LDM。
2. 通过向模型视频帧添加时间层,将图像 LDM 转变为视频 LDM。
3. 微调编码视频序列上的视频 LDM 以创建视频生成器。
4. 临时对齐扩散模型上采样器以生成高分辨率视频。
5. 在 512×1024 分辨率的真实驾驶视频上验证 Video LDM,实现最先进的性能。
6. 将此方法应用于具有文本到视频建模的创意内容创建。
论文地址:
https://arxiv.org/abs/2304.08818
在扩散模型 (LDM) 可实现高质量图像合成,同时通过在压缩的低维潜在空间中训练扩散模型来避免过多的计算需求。在这里,我们将 LDM 范例应用于高分辨率视频生成,这是一项特别耗费资源的任务。我们首先仅在图像上预训练 LDM;然后,我们通过将时间维度引入潜在空间扩散模型并对编码图像序列(即视频)进行微调,将图像生成器转变为视频生成器。同样,我们在时间上对齐扩散模型上采样器,将它们变成时间一致的视频超分辨率模型。我们专注于两个相关的现实世界应用:模拟野外驾驶数据和使用文本到视频建模的创意内容创建。尤其,我们在分辨率为 512 x 1024 的真实驾驶视频上验证了我们的视频 LDM,实现了最先进的性能。此外,我们的方法可以轻松利用现成的预训练图像 LDM,因为在这种情况下我们只需要训练时间对齐模型。这样做,我们将公开可用的、最先进的文本到图像 LDM 稳定扩散转变为分辨率高达 1280 x 2048 的高效且富有表现力的文本到视频模型。我们表明,时间层经过训练以这种方式推广到不同的微调文本到图像 LDM。利用此属性,我们展示了个性化文本到视频生成的第一个结果,为未来的内容创建开辟了令人兴奋的方向。项目页面:我们的方法可以轻松利用现成的预训练图像 LDM,因为在这种情况下我们只需要训练时间对齐模型。这样做,我们将公开可用的、最先进的文本到图像 LDM 稳定扩散转变为分辨率高达 1280 x 2048 的高效且富有表现力的文本到视频模型。我们表明,时间层经过训练以这种方式推广到不同的微调文本到图像 LDM。利用此属性,我们展示了个性化文本到视频生成的第一个结果,为未来的内容创建开辟了令人兴奋的方向。项目页面:我们的方法可以轻松利用现成的预训练图像 LDM,因为在这种情况下我们只需要训练时间对齐模型。这样做,我们将公开可用的、最先进的文本到图像 LDM 稳定扩散转变为分辨率高达 1280 x 2048 的高效且富有表现力的文本到视频模型。我们表明,时间层经过训练以这种方式推广到不同的微调文本到图像 LDM。利用此属性,我们展示了个性化文本到视频生成的第一个结果,为未来的内容创建开辟了令人兴奋的方向。项目页面:我们表明,以这种方式训练的时间层可以推广到不同的微调文本到图像 LDM。利用此属性,我们展示了个性化文本到视频生成的第一个结果,为未来的内容创建开辟了令人兴奋的方向。项目页面:我们表明,以这种方式训练的时间层可以推广到不同的微调文本到图像 LDM。利用此属性,我们展示了个性化文本到视频生成的第一个结果,为未来的内容创建开辟了令人兴奋的方向。
演示地址:
https://research.nvidia.com/labs/toronto-ai/VideoLDM/
本文地址:https://www.163264.com/2439