

RedPajama是一个完全开源的语言模型计划,旨在打造领先的开源模型。该项目第一阶段已完成,复现了LLaMA培训数据集超过1.2万亿个标记。RedPajama的三个关键组成部分包括预训练数据、基础模型和调整数据和模型。研究者可在Github上获取数据预处理和质量筛选的全部内容,并使用Meerkat面板和嵌入版进行交互式分析。RedPajama还将类似于开源项目Stable Diffusion和LLaMA的模型纳入其计划,目前正处于建模阶段。
https://www.together.xyz/blog/redpajama
翻译内容:
GPT-4 等基础模型推动了 AI 的快速改进。然而,最强大的模型是封闭的商业模型或仅部分开放。RedPajama 是一个创建一组领先的、完全开源模型的项目。今天,我们很高兴地宣布完成该项目的第一步:复制超过 1.2 万亿个代币的 LLaMA 训练数据集。
当今最强大的基础模型封闭在商业 API 之后,这限制了研究、定制及其对敏感数据的使用。如果开放社区能够弥合开放模型和封闭模型之间的质量差距,完全开源模型有望消除这些限制。最近,这方面取得了很大进展。在许多方面,AI 正在迎来它的 Linux 时刻。Stable Diffusion 表明,开源不仅可以与 DALL-E 等商业产品的质量相媲美,还可以通过全球社区的广泛参与带来令人难以置信的创造力。随着最近发布的LLaMA、Alpaca、Vicuna等半开放模型,类似的运动已经围绕大型语言模型展开, 和考拉; 以及完全开放的模型,如Pythia、OpenChatKit、Open Assistant和Dolly。
我们正在推出 RedPajama,旨在产生可重现的、完全开放的、领先的语言模型。RedPajama 是 Together、 Ontocord.ai、ETH DS3Lab、Stanford CRFM、Hazy Research和MILA Québec AI Institute之间的合作。RedPajama 具有三个关键组件:
-
预训练数据,既要高质量又要覆盖面广
-
基础模型,根据这些数据进行大规模训练
-
指令调整数据和模型,改进基础模型以使其可用和安全
今天,我们发布了第一个组件,预训练数据。
“ RedPajama 基础数据集是一个 1.2 万亿代币的完全开放数据集,它是按照 LLaMA 论文中描述的配方创建的。”
我们的起点是LLaMA,它是领先的开放基础模型套件,原因有二:首先,LLaMA 是在一个非常大的(1.2 万亿个代币)数据集上训练的,该数据集经过仔细过滤以确保质量。其次,70 亿参数的 LLaMA 模型经过更长时间的训练,远远超出了 Chincilla 最佳点,以确保在该模型大小下的最佳质量。70 亿参数模型对于开放社区特别有价值,因为它可以在各种 GPU 上运行,包括许多消费级 GPU。然而,LLaMA 及其所有衍生物(包括羊驼、骆马和考拉)仅可用于非商业研究目的。我们的目标是创建 LLaMA 的完全开源复制品,可用于商业应用,并为研究提供更透明的管道。
RedPyjama 基础数据集
完整的 RedPajama 1.2 万亿代币数据集和一个更小、更易消耗的随机样本可以通过Hugging Face下载。完整的数据集在磁盘上解压缩后约为 5TB,压缩后的下载量约为 3TB。
RedPajama-Data-1T 由七个数据片组成:
-
CommonCrawl:CommonCrawl 的五个转储,使用 CCNet 管道进行处理,并通过多个质量过滤器进行过滤,包括选择类似维基百科页面的线性分类器。
-
C4:标准 C4 数据集
-
GitHub:GitHub 数据,按许可证和质量过滤
-
arXiv:去除样板文件的科学文章
-
书籍:开放书籍的语料库,根据内容相似性进行去重
-
维基百科:维基百科页面的子集,删除样板
-
StackExchange:StackExchange 下流行网站的一个子集,去除了样板文件
对于每个数据切片,我们进行仔细的数据预处理和过滤,并调整我们的质量过滤器以大致匹配LLaMA 论文中Meta AI报告的标记数量:
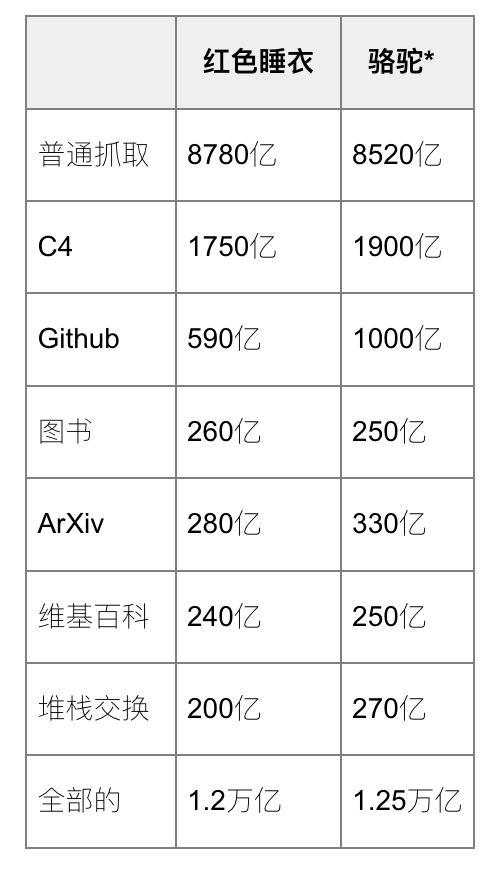
我们正在Github上公开提供所有数据预处理和质量过滤器。任何人都可以按照数据准备方法复制 RedPajama-Data-1T。
交互式分析 RedPajama 基础数据集
我们与Meerkat项目合作,发布了一个 Meerkat 仪表板和嵌入,用于探索语料库的 Github 子集。下图显示了仪表板的预览。
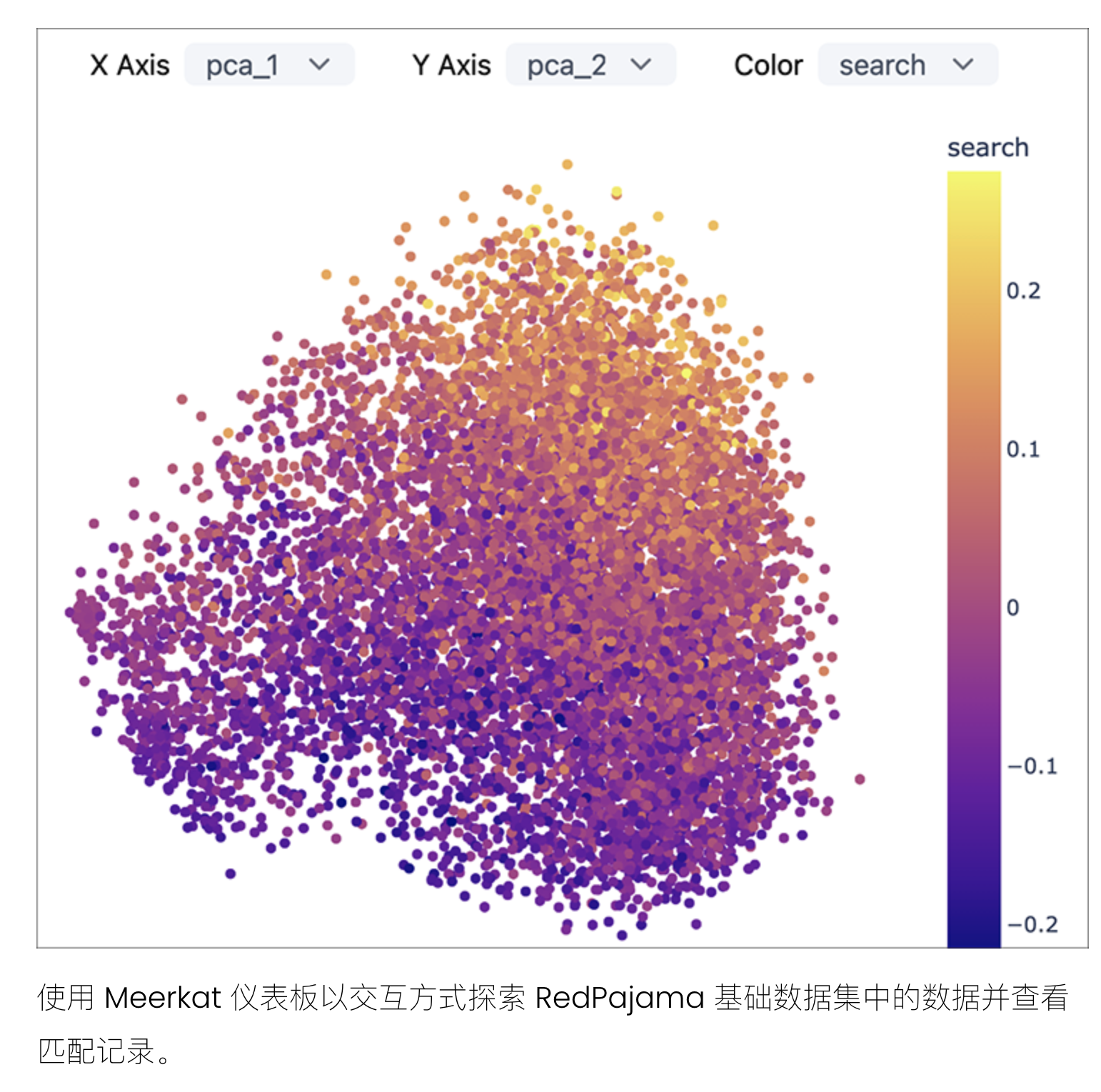
您可以在Github上找到有关如何安装和使用仪表板的说明。
接下来:模型、说明和 OpenChatKit
重现预训练数据后,下一步就是训练一个强大的基础模型。作为INCITE 计划的一部分,在橡树岭领导力计算设施 (OLCF)的支持下,我们正在训练一整套模型,第一个模型将在未来几周内可用。
有了强大的基础模型,我们很高兴能够指导调整模型。Alpaca展示了指令调优的力量——仅需 5 万条高质量、多样化的指令,它就能够解锁显着改进的功能。通过 OpenChatKit,我们收到了数十万条高质量的自然用户指令,这些指令将用于发布 RedPyjama 模型的指令优化版本。
本文地址:https://www.163264.com/2429