从AutoGPT谈起,看大语言模型使用工具的发展 这两天,推上最热话题莫过AutoGPT。 AutoGPT的目的是让大语言模型使用外部工具(例如google)完成复杂任务,这与我最近读的论文话题一致。
此thread读书笔记,从AutoGPT的源码出发谈论它的局限性,以及简短地总结几篇文章来看LLM使用工具的发展。


亮点是,通过constraints和performance evaluations要求llm使用缓存,并强行要求输出json格式,键值包含了所谓的reasoning和planning,以及选中的command api。 这其中的reasoning引起了我的注意,它真的有在reasoning么?
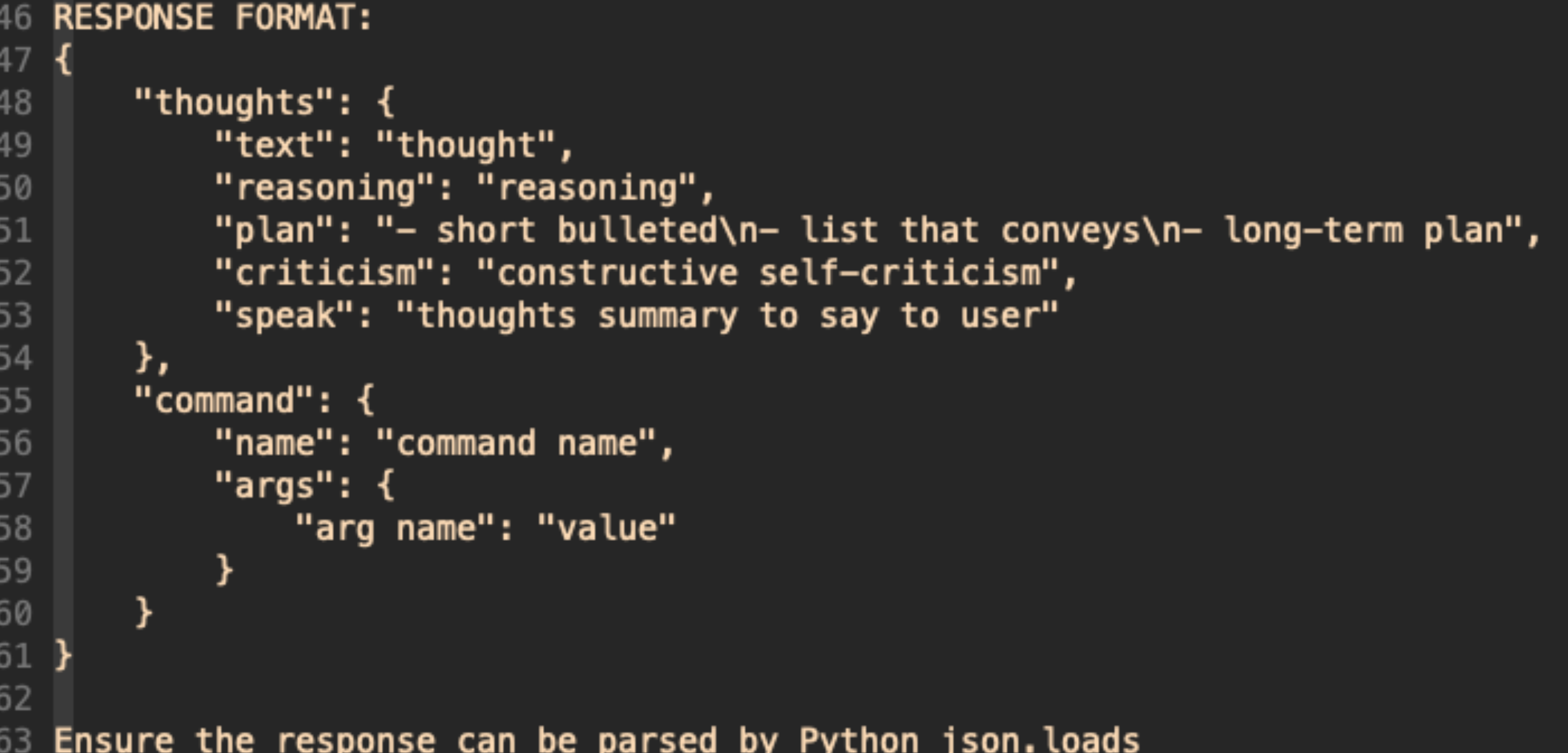
阅读我之前的CoT和ReAct的读者已经知道,大语言模型的推理(reasoning)是一种涌现行为,具体指:只有在引入CoT之后,超过1000亿参数的大模型才能解锁reasoning能力。
可以确定的是,AutoGPT的prompting 方式没有显性的引入CoT,所以没有解锁reasoning。 它只能严重依赖缓存做desicion making,一遍遍的重复action,有勇无谋,可以说它并没有真正在做reasoning。
在以token计费的背景下,这种局限性被放大,徒有炫酷,让一般开发者望而却步。
大语言模型学习使用工具和调用api的发展历程,大概以CoT和ReAct为界。 CoT和ReAct之前,大语言模型主要靠昂贵的human feedback来做reinfocement learning来学会call api。 例如 WebGPT: 让LLM学会调用bing search api
https://arxiv.org/abs/2112.09332
ReAct 将CoT动态地引入到LLM学习call api的过程中,用CoT大道至简的思想,让LLM在完成api calling这个decision making前,具有推理过程,轻量级地解决了模型学习api的问题。
ReAct的进阶MM-REACT MM-REACT是ReAct的进阶,通过运用ReAct的思想,完成多模态复杂任务。 MM-REACT把ChatGPT作为智能coordinator,协调视觉专家模型完成任务,特别的是,MM-REACT显性地用thought/action/observation这种ReAct模式进行prompting。
https://arxiv.org/abs/2303.11381

当我们回顾LLM的使用工具的发展,随着模型越来越大,带来的变化是: 1: 做fintune或用human feedback reinforcement learning越来越昂贵。 2: 大模型的涌现能力,让zero-shot/few-shot成为潮流。
在这一潮流中CoT扮演了重要的角色,它解锁了模型涌现推理能力,帮助llm完成了对自身知识的潜能挖掘;
ReAct将CoT推进到了大模型运用外部工具的层面,弥补了大模型依赖预训练知识的局限性;
MM-ReAct进一步将拓展了语言模型的应用边界,超越了语言文字的范畴。
如果此时在此回看AutoGPT, 发现它在middle of no where,它是prompting的本质,既没有reinforcement learning的加持,又没有CoT,它像一个实习生,动力十足,但思维跟不上。
但CoT本质也是prompting,它是如此轻成本,如果AutoGPT引入CoT, 会更可怕。
最近感受是,每次的thread仿佛在写一篇小的综述,这一过程让我自己也获益匪浅,感谢我的读者的激励。thread中有任何错误和疑问,欢迎指出,大家一起讨论,共同成长。
本文地址:https://www.163264.com/1885