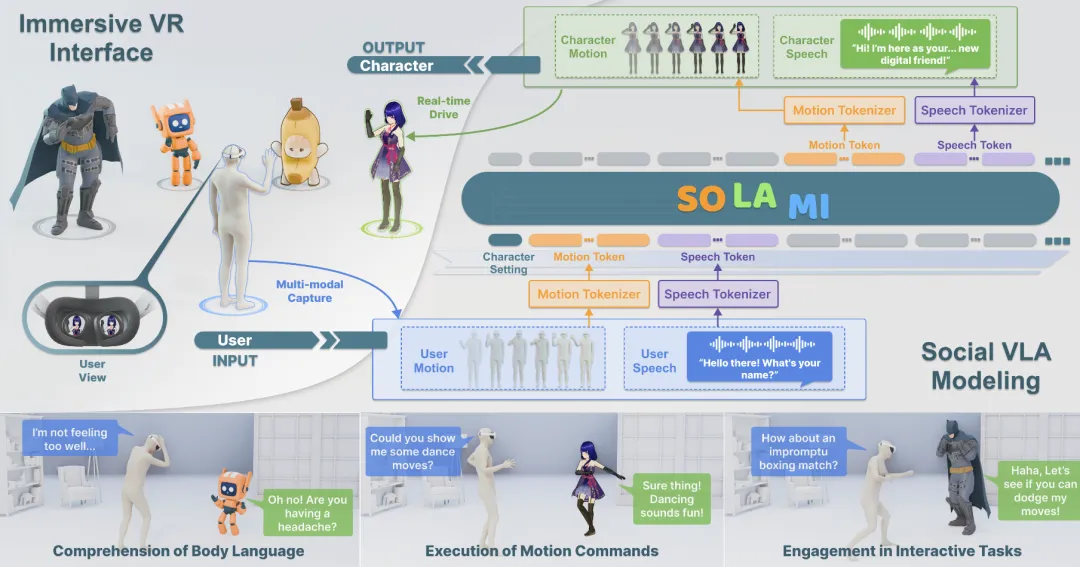

根据您的请求,以下是关于端到端的社会视觉-语言-动作建模框架SOLAMI的详细介绍:
- 框架简介:
SOLAMI是由商汤科技推出的首个端到端的“社交视觉-语言-行动”(VLA)建模框架,专为与3D自主角色进行沉浸式互动而设计。它允许用户在沉浸式VR环境中通过语音和肢体语言与3D自主角色进行交互。 - 核心构建方面:
SOLAMI通过三个核心方面构建3D自主角色:
- 社会VLA架构:提出了一个统一的社会VLA框架,根据用户的多模态输入生成语音和动作响应,驱动角色进行社交互动。
- 交互式多模态数据:创建了名为SynMSI的合成多模态社交数据集,通过自动化流程解决数据稀缺问题。
- 沉浸式VR界面:开发了沉浸式VR界面,使用户能够与不同架构驱动的角色进行更加真实的互动。
- 技术原理:
SOLAMI使用端到端的社交视觉-语言-动作模型,在合成的多模态数据集SynMSI上进行训练。在预训练阶段,使用动作文本和语音文本相关任务来训练模型,以使语音和动作模式与语言保持一致。在指令调整阶段,使用社交多模态多轮交互数据来训练模型,使其能够生成与角色设置和主题上下文一致的多模态响应。 - 应用场景:
SOLAMI的应用场景广泛,包括但不限于:
- 物体识别与抓取:机器人通过视觉和语言指令识别并抓取特定物体。
- 多步骤操作:执行如“将胡萝卜放在橙色盘子上”等复杂指令。
- 动作规划:机器人根据指令执行搬运、摆放等一系列动作。
- 优势与挑战:
- 优势:SOLAMI结合了先进的视觉和语言模型,能够处理复杂的语言指令,并且作为开源模型,促进了社区的共同进步和创新。
- 挑战:目前SOLAMI主要支持单图像输入,未来需要扩展至多图像和多感官输入,同时大规模训练需要高性能计算资源,对于一般研究团队可能存在门槛。
SOLAMI的推出标志着视觉-语言-动作模型在社会交互领域的新进展,为3D自主角色的社交智能提供了新的解决方案。
项目地址:
本文地址:https://www.163264.com/10182