
Adobe与MIT合作推出的CausVid视频生成模型是一项突破性技术,它能够实现实时视频生成,极大地提升了视频内容创作的效率。以下是CausVid的一些关键特性:
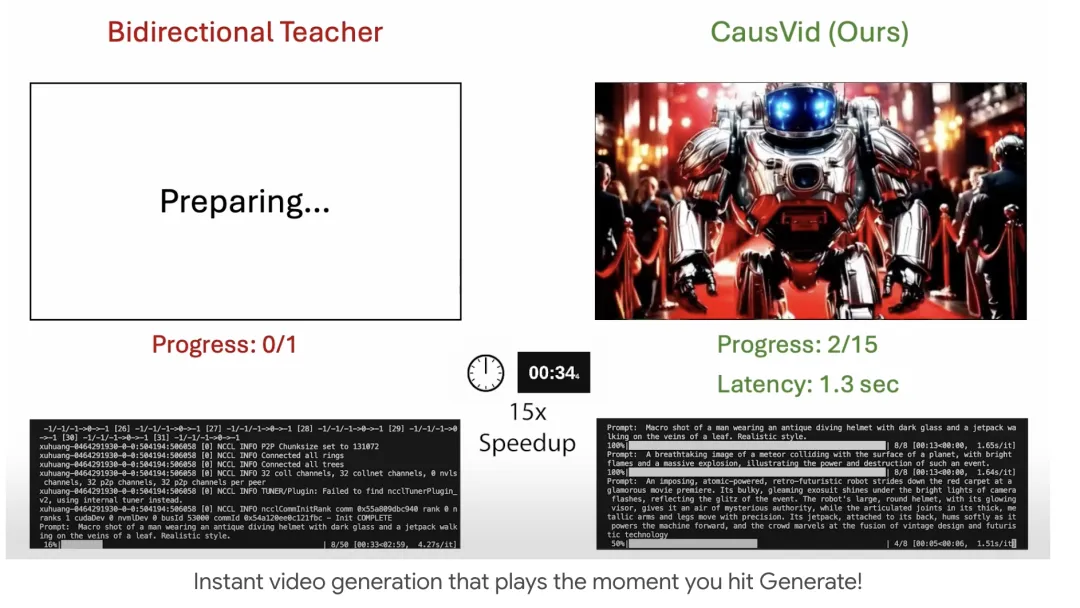
- 自回归实时视频生成技术:CausVid能够即时播放视频,模型生成首帧画面后,视频便可以即时播放,后续内容动态生成并无缝衔接。
- 快速生成速度:CausVid以每秒9.4帧的速度实时生成高质量视频,首帧延迟仅需1.3秒。
- 技术原理:CausVid基于自回归生成模型,按顺序生成视频的每一帧。它采用分布匹配蒸馏(DMD)技术,将一个多步的扩散模型蒸馏成只需4步的生成器,大幅减少生成步骤,提高效率。
- 非对称蒸馏策略:CausVid使用双向教师模型监督自回归的单向学生模型,减少误差累积,提高视频生成质量。
- 学生初始化:在蒸馏训练之前,基于预训练学生模型稳定后续的训练过程。
- KV缓存推理技术:CausVid使用键值(KV)缓存机制,提高生成效率,支持模型快速访问之前生成的帧信息。
- 滑动窗口机制:CausVid采用滑动窗口机制,处理无限长度的视频生成,打破传统模型的长度限制。
- 误差累积控制:基于教师-学生结构和特定的训练策略,减少自回归模型中常见的误差累积问题,生成更稳定和高质量的视频内容。
- 应用场景广泛:CausVid支持多种视频生成任务,包括文本到视频、图像到视频、视频到视频转换和动态提示等,所有这些任务都能以极低的延迟完成。
- 开源计划:研究团队表示将很快开源基于开源模型的实现代码。
CausVid的出现标志着视频生成领域的一次重大突破,它将彻底改变我们创作和消费视频内容的方式,开启一个充满无限可能性的未来。
项目地址:
本文地址:https://www.163264.com/10170