
谷歌已经正式发布了新一代的AI模型Gemini 2.0,这标志着谷歌在人工智能领域的又一重大进展。以下是Gemini 2.0的一些关键特性和亮点:
- 多模态输入与输出:Gemini 2.0支持处理文本、图像、音频和视频等多种输入类型,并且能够生成图像和音频内容,扩展了AI在跨媒体任务中的应用范围。
- 自主代理功能:Gemini 2.0能够代替用户执行复杂的任务和决策,不仅能进行信息查询,还能自动化处理多步骤任务,如撰写报告、整理数据、进行决策分析等。
- 增强推理和规划能力:相比于前版本,Gemini 2.0在推理和问题解决上更加深入,能够处理复杂的多步骤任务,提供详细的思考过程和分步执行方案。
- 灵活的工具调用:Gemini 2.0具备强大的扩展性,可以调用Google自家的工具(如Google搜索、Lens、地图等)以及第三方工具或函数,极大地增强了其灵活性和功能。
- 深度集成于Google生态:Gemini 2.0深度集成到Google的多项服务中,如Google搜索、Google Chrome浏览器以及Google助手等,这使得用户可以直接在这些平台上利用Gemini 2.0完成任务。
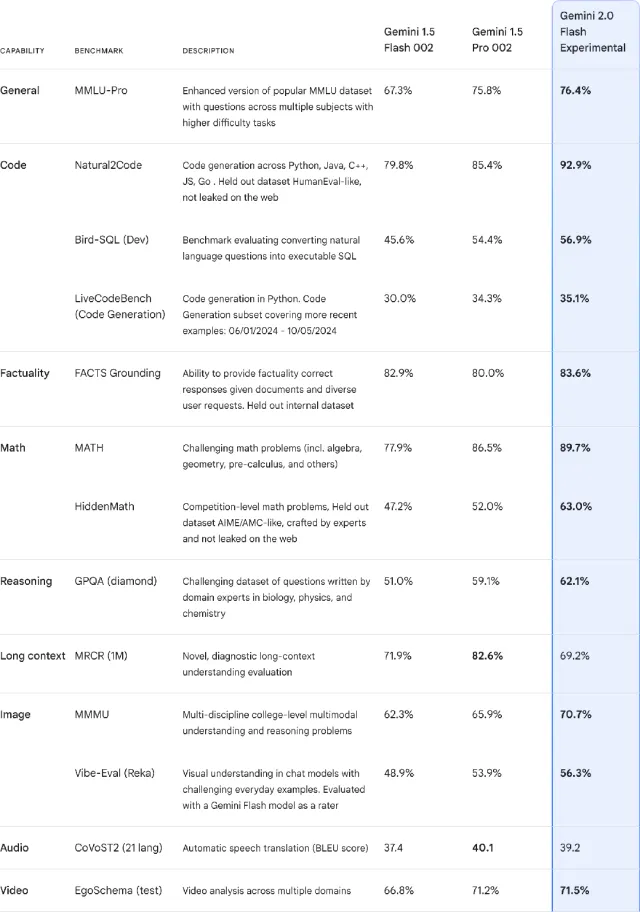
- 性能提升:在关键基准测试中,Gemini 2.0不仅超越了1.5 Pro的表现,速度更提升了一倍。
- 新功能和Agent:Gemini 2.0引入了多项新的Agent功能,包括Project Astra、Project Mariner、Jules和游戏Agent,这些功能覆盖了从游戏辅助到编程助手等多个领域。
- 免费API试用:Gemini 2.0 Flash及API免费可用,可以通过Google AI Studio和Vertex AI中的Gemini API使用,每分钟最多15个提问,每天最多1500个提问。
Gemini 2.0的发布,展示了谷歌在构建更智能、更自动化的AI代理方面的雄心,这些代理能够理解环境、执行任务并在一定程度上独立做出决策。这不仅是技术上的一次飞跃,也为用户带来了更加丰富和便捷的智能体验。
本文地址:https://www.163264.com/10160